Reinforcement learning for focusing and steering tasks
Use case: ARES linear accelerator at DESY
Implementation example for RL4AA'23 workshop
Today!
In this tutorial notebook we will implement all the basic components of a Reinforcement Learning algorithm to solve a problem in particle accelerators, focused on reward definition
- Part I: Introduction
- Part II: Algorithm implementation in Python
- Part III: Reward definition!
- Part IV: Training an RL agent
Part I: Introduction
ARES (Accelerator Research Experiment at SINBAD)
ARES is an S-band radio frequency linac at the DESY Hamburg site equipped with a photoinjector and two independently driven traveling wave accelerating structures. The main research focus is the generation and characterization of sub-femtosecond electron bunches at relativistic particle energy. The generation of short electron bunches is of high interest for radiation generation, i.e. by free electron lasers.

- Final energy: 100-155 MeV
- Bunch charge: 0.5-30 pC
- Bunch length: 0.2-10 fs
- Pulse repetition rate: 10-50 Hz
The accelerator problem we want to solve
We would like to focus and center the electron beam on a diagnostic screen using corrector and quadrupole magnets
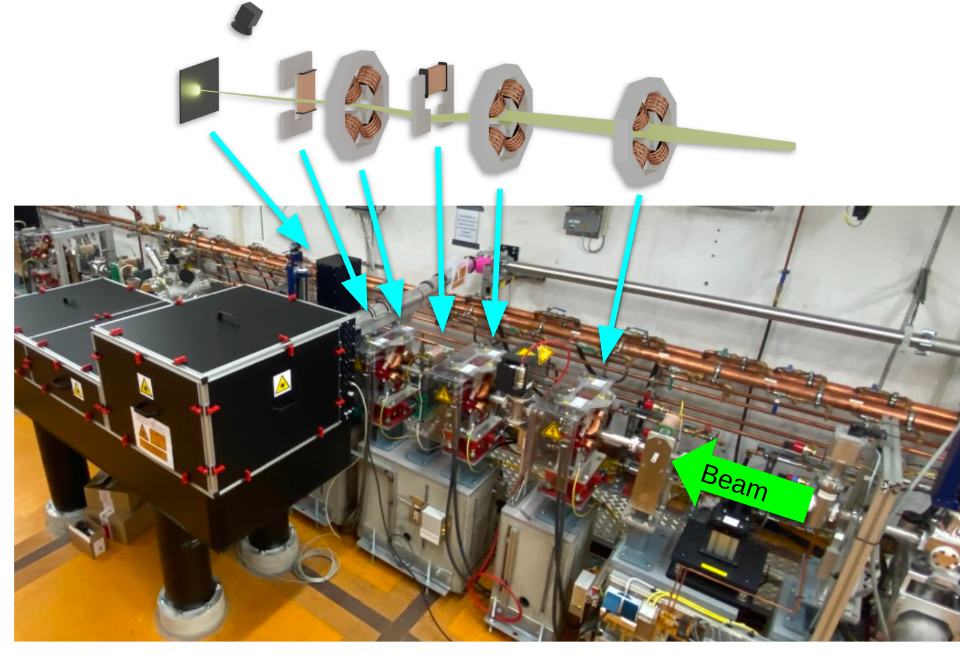
Formulating the RL problem
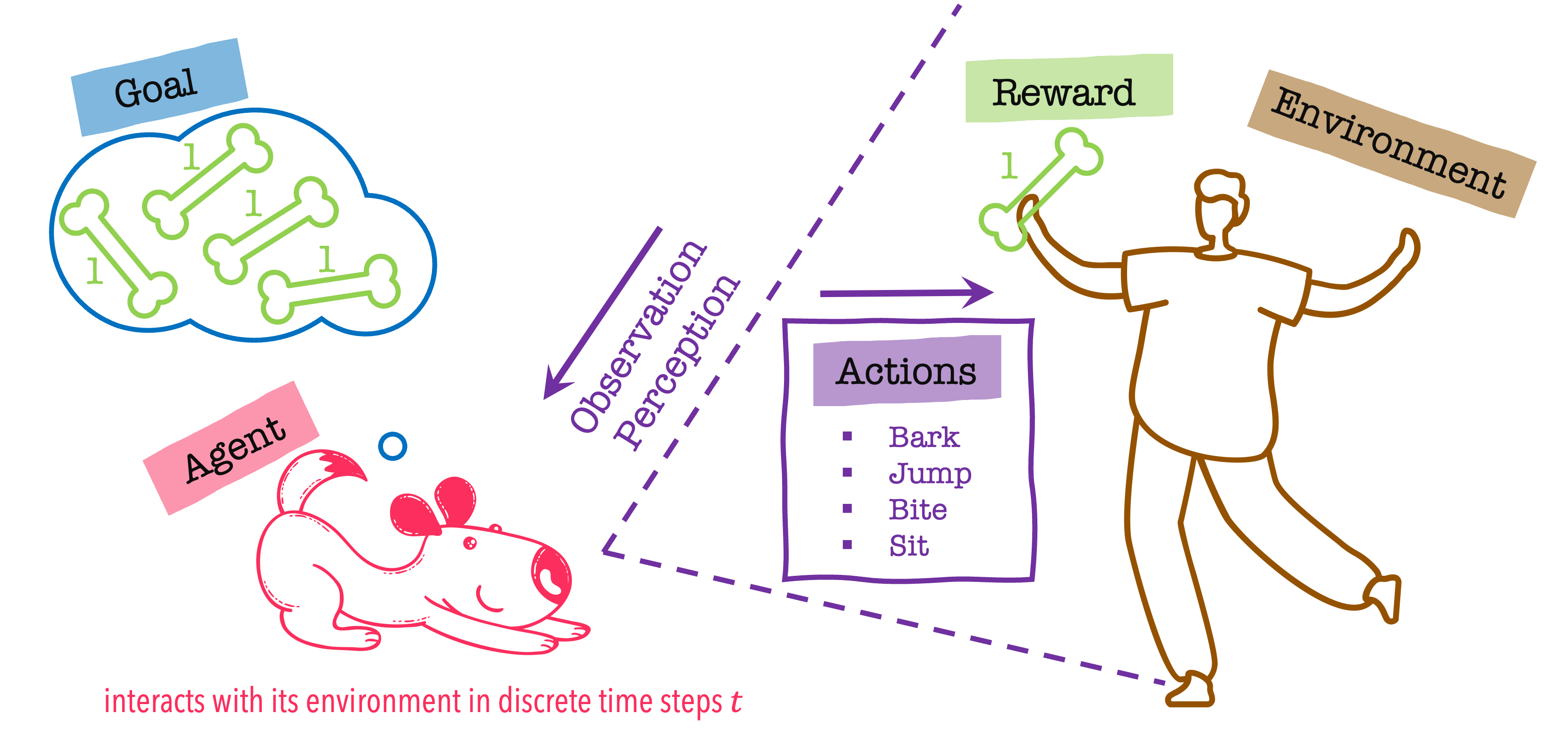
Refresher from the lecture
We need to define:
- Actions
- Observations
- Reward
- Environment
- Agent
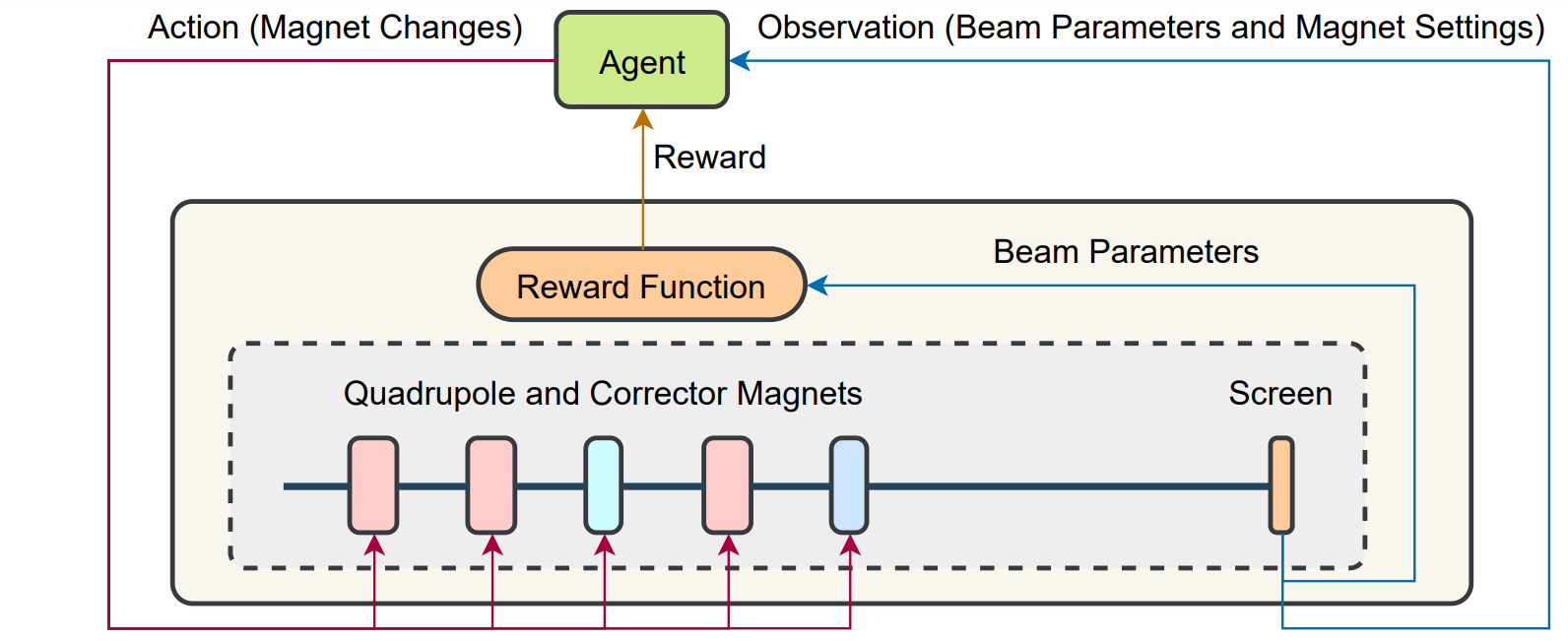
Formulating the RL problem
Overview of our study case
Discussion
$\implies$ Is the action space continuous or discrete?
$\implies$ Is the problem deterministic or stochastic?
Formulating the RL problem
Actions
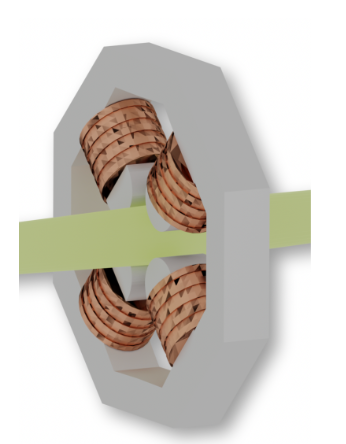
In the ARES transverse tuning task we have 3 quadrupoles and 2 corrector magnets
The actions are:
- Quadrupole magnet strength $k_{1,2,3}$ $[1/m^2]$
- Corrector deflection angle $\theta_\mathrm{v, h}$ $[mrad]$ (vertical and horizontal
In our control system we can set these derived values directly according the beam energy
$\implies$ actions $=[k_{\mathrm{Q1}},k_{\mathrm{Q2}},\theta_\mathrm{CV},k_{\mathrm{Q3}},\theta_\mathrm{CH}]$
is a 5-dimensional array
Formulating the RL problem
Observation / state
Observation is the information an agent receives about the current state of the environment
It should provide enough information so that the agent can solve this problem.
The observation does not necesearily cover the entire (internal) state pf the environment.
Discussion
$\implies$ What should be included in the observation?
$\implies$ What can be observed in simulation?
$\implies$ What cannot be observed in real world?
$\implies$ How does this relate to the environment?
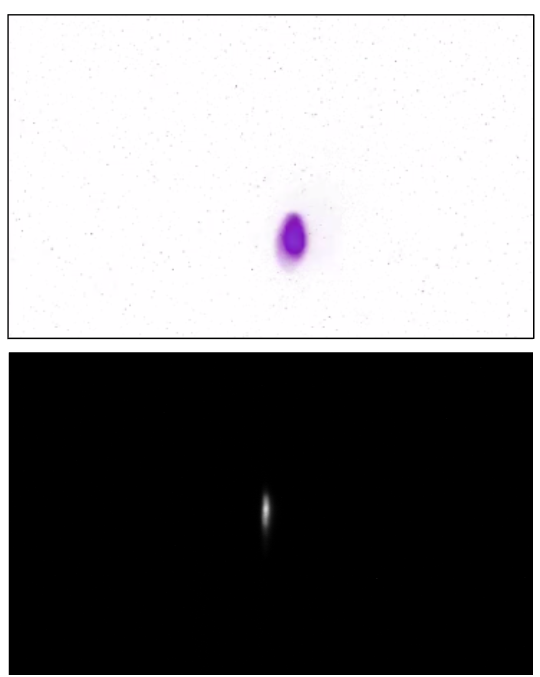
The screen is made from scintillating material and glows when hit by electrons
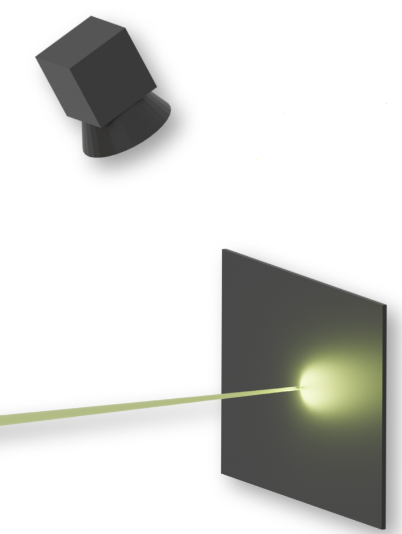
The camera films the screen
Formulating the RL problem
The environment's state
The state can be fully described by with four components:
- The target beam: the beam we want to achieve, our goal
- as a 4-dimensional array $b^\mathrm{(t)}=[\mu_x^{(\mathrm{t})},\sigma_x^{(\mathrm{t})},\mu_y^{(\mathrm{t})},\sigma_y^{(\mathrm{t})}]$, where $\mu$ denotes the position on the screen, $\sigma$ denotes the beam size, and $t$ stands for "target".
- The incoming beam: the beam that enters the EA upstream
- $I = [\mu_x^{(\mathrm{i})},\sigma_x^{(\mathrm{i})},\mu_y^{(\mathrm{i})},\sigma_y^{(\mathrm{i})},\mu_xp^{(\mathrm{i})},\sigma_xp^{(\mathrm{i})},\mu_yp^{(\mathrm{i})},\sigma_yp^{(\mathrm{i})},,\mu_s^{(\mathrm{i})},\sigma_s^{(\mathrm{i})}]$, where $i$ stands for "incoming"
- The magnet strengths and deflection angles
- $[k_{\mathrm{Q1}},k_{\mathrm{Q2}},\theta_\mathrm{CV},k_{\mathrm{Q3}},\theta_\mathrm{CH}]$
- The transverse misalignments of quadrupoles and the diagnostic screen
- $[m_{\mathrm{Q1}}^{(\mathrm{x})},m_{\mathrm{Q1}}^{(\mathrm{y})},m_{\mathrm{Q2}}^{(\mathrm{x})},m_{\mathrm{Q2}}^{(\mathrm{y})},m_{\mathrm{Q3}}^{(\mathrm{x})},m_{\mathrm{Q3}}^{(\mathrm{y})},m_{\mathrm{S}}^{(\mathrm{x})},m_{\mathrm{S}}^{(\mathrm{y})}]$
Discussion
$\implies$ Do we know or can we observe the state of the environment?
Formulating the RL problem
Our definition of observation
The observation for this task contains three parts:
- The target beam: the beam we want to achieve, our goal
- as a 4-dimensional array $b^\mathrm{(t)}=[\mu_x^{(\mathrm{t})},\sigma_x^{(\mathrm{t})},\mu_y^{(\mathrm{t})},\sigma_y^{(\mathrm{t})}]$, where $\mu$ denotes the position on the screen, $\sigma$ denotes the beam size, and $t$ stands for "target".
- The current beam: the beam we currently have
- $b^\mathrm{(c)}=[\mu_x^{(\mathrm{c})},\sigma_x^{(\mathrm{c})},\mu_y^{(\mathrm{c})},\sigma_y^{(\mathrm{c})}]$, where $c$ stands for "current"
- The magnet strengths and deflection angles
- $[k_{\mathrm{Q1}},k_{\mathrm{Q2}},\theta_\mathrm{CV},k_{\mathrm{Q3}},\theta_\mathrm{CH}]$
Discussion
$\implies$ Does this state definition fullfil the Markov property? (does the probability distribution for the next beam depend only on the present state? or is it affected by information about the past?)
Formulating the RL problem
Goal and reward
Our goal is divided in two tasks:
- to steer the beam to the desired positions
- to focus the beam to the desired beam size
Discussion
$\implies$ How should we define our reward function? Give it a go!
$\implies$ We have a whole section dedicated to reward formulation later on
Formulating the RL problem
Agent / algorithm
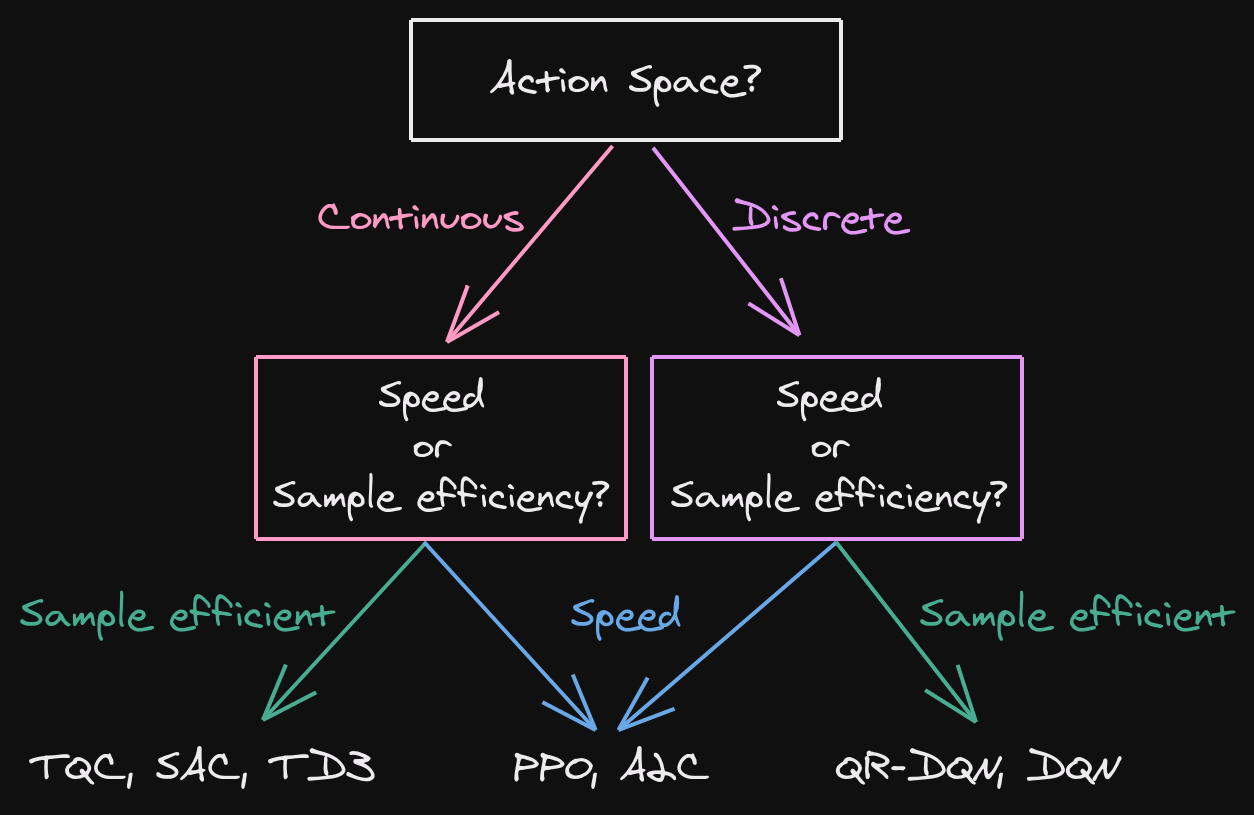
image from RL Tips and Tricks - A. Raffin
Discussion
$\implies$ What would you choose and why?
Part II: Algorithm implementation in Python
About libraries for RL
There are many libraries with already implemented RL algorithms, and frameworks to implement an environment to interact with. In this notebook we use:
- Stable-Baselines3 for the agents
- OpenAI Gym for the environment

More info here
Note: OpenAI Gym is slowly being succeeded by Gymnasium, a fork of Gym maintained by the Farama Foundation.
Agent / algorithm
- As mentioned, we use the Stable-Baselines3 (SB3) package to implement the reinforcement learning algorithms.
- In this tutorial we focus on two examples: PPO (proximal policy optimization) and TD3 (twin delayed DDPG)
Environment
We take all the elements of the RL problem we defined previously and reprensent the tuning task as an OpenAI Gym environment, which is a standard library for RL tasks.
A custom gym.Env would contain the following parts:
- Initialization: setup the environment, declares the allowed
observation_spaceandaction_space resetmethod: resets the environment for a new episode, returns 2-tuple(observation, info)stepmethod: main logic of the environment. It takes anaction, changes the environment to a newstate, get newobservation, compute thereward, and finally returns the 4-tuple(observation, reward, done, info)donechecks if the current episode should be terminated (reached goal reached, or exceeded some thresholds)
rendermethod: to visualize the environment (a video,or just some plots)
An overview of this RL project
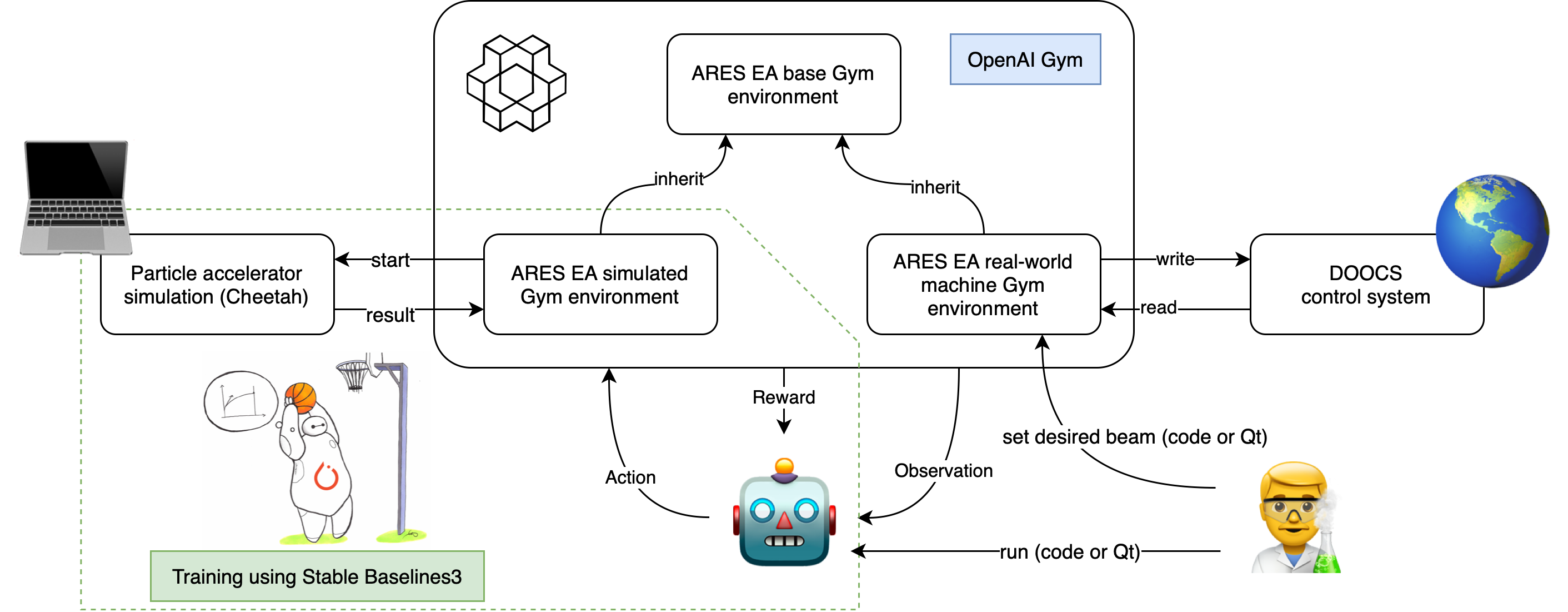
Code directory structure
We list the most relevant parts of the project structure below:
utils/train.pycontains the gym environments and the training scriptARESEAimplements the ARES Experimental Area transverse tuning task as agym.Env. It contains the basic logic, such as definition of observation space, action space, and reward. How an action is taken is implemented in child classes with specific backends.ARESEACheetahis derived from the base classARESEA, where it usescheetahsimulation as a backend.make_envInitializes aARESEAenvrionment, and wraps it with required gym.wrappers with convenient features (e.g. monitoring the progress, end episode when time_limit is reached, rescales the action, normalize the observation, ...)trainconvenient function for training the RL agent. It callsmake_env, setup the RL algorithm, starts training, and saves the results inutils/recordings,utils/monitorsandutils/models.
Code directory structure
We list the most relevant parts of the project structure below:
utils/helpers.pycontains some utility functionsevaluate_ares_ea_agentTakes a trained agent and evaluates its performance using different metrics.plot_ares_ea_training_historyshows the progress during training
What is Cheetah?
- RL algorithms require a large number of samples to learn ($10^5-10^9$), and getting those samples in the real accelerator is often too costly.
- This is why a common approach is to train the agent in simulation, and then deploy it in the real machine
- In our case we would train with optics simulation codes for accelerators, such as OCELOT
- These codes were developed to help the design phases of accelerators, but not to generate training data, making their computing time too high for RL.
- Cheetah is a tensorized approach for transfer matrix tracking, which saves computation time and overhead compared to OCELOT
from time import sleep
import matplotlib.pyplot as plt
import names
import numpy as np
from gym.wrappers import RescaleAction
from IPython.display import clear_output, display
from stable_baselines3 import PPO
from utils.helpers import (
evaluate_ares_ea_agent,
make_ares_ea_training_videos,
plot_ares_ea_training_history,
show_video,
)
from utils.train import ARESEACheetah, make_env, read_from_yaml
from utils.train import train as train_ares_ea
from utils.utils import NotVecNormalize
The ARESEA (ARES Experimental Area) Environment
- We formulated the ARESEA task as a OpenAI Gym environment, which allows our algorithm to easily interface with both the simulation and real machine backends as shown before.
- In this part, you will get familiar with the environment for the beam focusing and positioning at ARES accelerator.
Some methods:
reset: in both real and simulation cases: resets the magnets to initial values. In simulation, regenerate incoming beam, (optionally) resets the magnet misalignments.step: set magnets to new settings. Observe the beam (run a simulation or observe screen image in real-world).
Now let's create the environment:
# Create the environment
env = ARESEACheetah()
env.target_beam_mode = "constant"
Set a target beam you want to achieve
$\implies$ Let's define the position $(\mu_x, \mu_y)$ and size $(\sigma_x, \sigma_y)$ of the beam on the screen
$\implies$ Modify the target_beam list below, where the order of the arguments is $[\mu_x,\sigma_x,\mu_y,\sigma_y]$
$\implies$ Take into account the dimensions of the screen ($\pm$ 2e-3 m)
$\implies$ The target beam will be represented by a blue circle on the screen
target_beam = np.array([1e-3, 2e-4, 1e-3, 2e-4]) # Change it
env.target_beam_values = target_beam
env.reset() ##
plt.figure(figsize = (7, 4))
plt.imshow(env.render(mode="rgb_array")) # Plot the screen image
<matplotlib.image.AxesImage at 0x7f596835a260>

Get familiar with the Gym environment
$\implies$ Change the magnet values, i.e. the actions
$\implies$ The actions are normalized to 1, so valid values are in the [0, 1] interval
$\implies$ The values of the action list in the cell below follows this magnet order: [Q1, Q2, CV, Q3, CH]
action = np.array([1, 0.5, 0.5, 1, 0.6]) # put your action here
Perform one step: update the env, observe new beam!
env = RescaleAction(env, -1, 1) # rescales the action to the interval [-1, 1]
env.reset()
env.step(action)
plt.figure(figsize = (7, 4))
plt.imshow(env.render(mode="rgb_array"))
<matplotlib.image.AxesImage at 0x7f59683e5fc0>

$\implies$ Observe the plot above, what beam does that magnet configuration yield? can you center and focus the beam by hand?
- Let's now use the environment in a loop, and perform 10 steps
- The function below will linearly vary the value of the vertical corrector
env.reset()
steps = 10
def change_vertical_corrector(q1, q2, cv, q3, ch, steps, i):
action = np.array([q1, q2, cv + 1 / steps * i, q3, ch])
return action
fig, ax = plt.subplots(1, figsize = (7, 4))
for i in range(steps):
action = change_vertical_corrector(0.2, -0.2, -0.5, 0.3, 0, steps, i)
env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Part III: Reward definition!
- In the following, we reduce our problem to only focusing of the beam, and actuators to only 3 quadrupole magnets
- In this way, we can train a RL agent with fewer steps
Training a good agent revolves primarily around finding the right setup for the environment and the correct reward function. In order to iterate over and compare many different options, our training function takes a dictionary called config. The dictionary keys or "configurations" are explained below
Configurations
In the following, we use a config dictionary to set up the training. This allows us to easily switch between different training conditions. Below we show some selected configurations that have the most influence on training results, the parameters can mostly be divided into two parts.
Configurations
Environment configurations
action_modeSet directly the magnet strength or set a delta action. You may set this to"direct"or"delta". You should find that "delta" trains faster. Setting "delta" is also crucial in running the agent on the real accelerator.reward_mode: How the reward is calculated. Can be set tonegative_objective,objective_improvement, orsum_of_pixels.time_reward: Whether the agent will be penalized for making another step, this is intended to make the tuning faster.rescale_action: Takes the limits of the magnet settings and scale them into the following range.
Configurations
Environment configurations
Termination conditions:
abort_if_off_screenIf this property is set to True, episodes are aborted when the beam is no longer on the screen.time_limit: Number of interactions the agent gets to tune the magnets within one episode.target_sigma_x_threshold,target_sigma_y_threshold: Thresholds for beam parameters. If all beam parameters are within the threshold from their target, episodes will end and the agent will stop optimising.
Question
$\implies$ What does the existence of termination conditions says about the nature of the problem? is it episodic or continuous?
What could go wrong?
Let's load some pre-trained models using different combinations of the config dictionary and using different reward definitions
Pre-trained Agent 1: "Gary Buchwald"
Relevant config parameters
"abort_if_off_screen": True"reward_mode": "objective_improvement""target_sigma_x_threshold": None"target_sigma_y_threshold": None"time_reward": -1.0"action_mode": "delta"
Reward = objective_improvement
Difference of the objective:
$$ r_\mathrm{obj-improvement} = ( \mathrm{obj}_{j-1} - \mathrm{obj}_{j} ) / \mathrm{obj}_0 $$$$ obj = \sum_{i}|b_i^\mathrm{(c)} - b_i^\mathrm{(t)}|$$where $j$ is the index of the current time step.
Question
$\implies$ What do you expect to happen, why?
agent_name = "Gary Buchwald" # names are randomly generated in training
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=False)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Pre-trained Agent 2: "David Archibald"
Relevant config parameters
"abort_if_off_screen": False"reward_mode": "sum_of_pixels""target_sigma_x_threshold": None"target_sigma_y_threshold": None"time_reward": 0.0"action_mode": "delta"
Reward = sum_of_pixels (focusing-only)
$$r_\mathrm{sum-pixel} = - \sum_\text{all pixels} \text{pixel-value}$$
Question
$\implies$ What do you expect to happen, why?
agent_name = "David Archibald" # names are randomly generated in training
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=False)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Pre-trained Agent 3: "Bertha Sparkman"
Relevant config parameters
"abort_if_off_screen": False"reward_mode": "objective_improvement""target_sigma_x_threshold": None"target_sigma_y_threshold": None"time_reward": 0.0"action_mode": "direct"
Reward = objective_improvement
Difference of the objective:
$$ r_\mathrm{obj-improvement} = ( \mathrm{obj}_{j-1} - \mathrm{obj}_{j} ) / \mathrm{obj}_0 $$$$ obj = \sum_{i}|b_i^\mathrm{(c)} - b_i^\mathrm{(t)}|$$where $j$ is the index of the current time step.
Question
$\implies$ What do you expect to happen?
$\implies$ What is the difference between Agent 1: "Gary Buchwald" and this agent?
agent_name = "Bertha Sparkman" # names are randomly generated in training
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=False)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Pre-trained Agent 4: "Betty Gordon"
Relevant config parameters
"abort_if_off_screen": False"reward_mode": "objective_improvement""target_sigma_x_threshold": None"target_sigma_y_threshold": None"time_reward": 0.0"action_mode": "delta"
Reward = objective_improvement
Difference of the objective:
$$ r_\mathrm{obj-improvement} = ( \mathrm{obj}_{j-1} - \mathrm{obj}_{j} ) / \mathrm{obj}_0 $$$$ obj = \sum_{i}|b_i^\mathrm{(c)} - b_i^\mathrm{(t)}|$$where $j$ is the index of the current time step.
Question
$\implies$ What do you expect to happen?
$\implies$ What is the difference between Agent 1: "Gary Buchwald", Agent 3: "Bertha Sparkman", and this agent?
agent_name = "Betty Gordon" # names are randomly generated in training
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=False)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Pre-trained Agent 5: "Sean Kelley"
Relevant config parameters
"abort_if_off_screen": False"reward_mode": "negative_objective""target_sigma_x_threshold": None"target_sigma_y_threshold": None"time_reward": 0.0"action_mode": "delta"
Reward = negative_objective"
$$ \mathrm{obj} = \sum_{i}|b_i^\mathrm{(c)} - b_i^\mathrm{(t)}|$$
$$ r_\mathrm{neg-obj} = -1 * \mathrm{obj} / \mathrm{obj}_0 $$where $b = [\mu_x,\sigma_x,\mu_y,\sigma_y]$, $b^\mathrm{(c)}$ is the current beam, and $b^\mathrm{(t)}$ is the target beam. $\mathrm{obj}_0$ is the initial objective after reset.
Question
$\implies$ What do you expect to happen, why?
agent_name = "Sean Kelley" # names are randomly generated in training
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=False)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Part IV: Training an RL agent
What is inside an actor-critic agent like PPO?
- An
actor model, often a neural network, takes theobservationof the currentstateand predicts anactionto be taken (forward pass)- In the ARES case, it observes the accelerator and predicts the magnet settings
- A
critic model, also a neural network, takes theobservationof the currentstateand predicts the value function of the state (and evaluates how good is the action taken by theactor model)
What actually happens when you train a PPO agent?
Step 1: collect samples
n_samples = n_steps * n_envsis the total number of samples, or interactions with the environment in oneepoch(more on what that means later)- One sample is collected at each step
- We can initialize
n_envsparallel environments, in which the agent will taken_steps - The total number of samples then has to account for the samples gathered in all environments
At each step:
- The agent will take actions according to the current
actor modelprediction (forward pass of the model NN) - The
critic modelwill predict the value functions of the states during the episode (forward pass of the model NN)
The samples (actions, rewards,...) from all environments are stored in a buffer, where buffer_size = n_samples
What actually happens when you train a PPO agent?
Step 2: update the models (weights of NNs)
After performing n_steps in a particular environment (and therefore gathering n_steps number of samples per environment), it's time to update the actor and critic models (backpropagation of the NNs). Let's consider only 1 environment now for simplicity.
- One can split the
n_samplesin mini-batches of a certainbatch_size- This means that the model will be completely updated (i.e. has seen all the samples) after
n_samples_tot/batch_sizenumber of backpropagations - Once the model is updated, it can be trained again on the same samples a certain number of
n_epochs(number of iterations on the training set) - This process can be repeated a certain number of
epochs(yes...) - The total number of samples across the epochs is
total_timesteps, wheretotal_timesteps = n_steps * n_envs * n_epochs = n_samples * n_epoch
- This means that the model will be completely updated (i.e. has seen all the samples) after
What actually happens when you train a PPO agent?
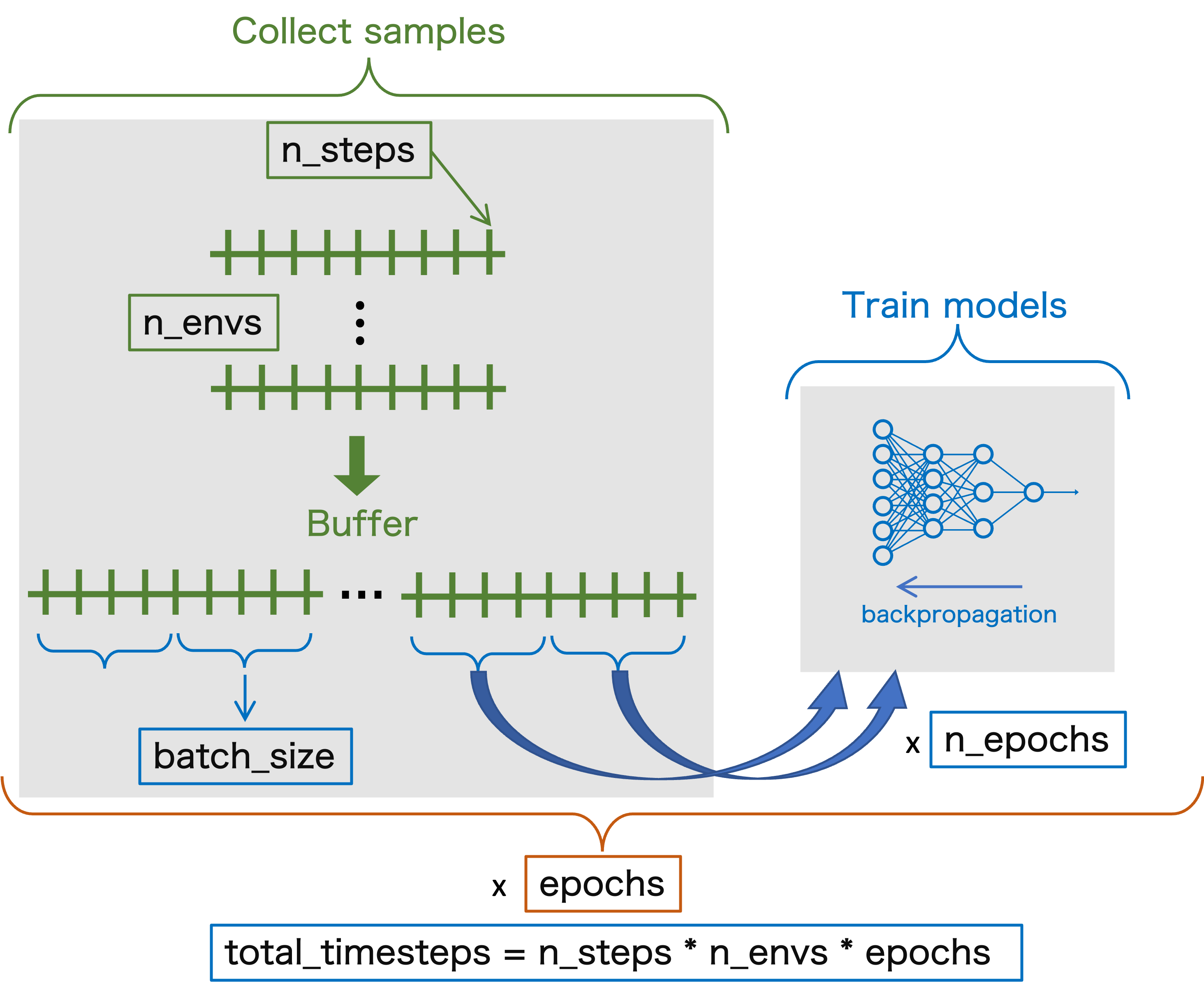
Question
$\implies$ What the advantage of having a buffer?
What actually happens when you train a PPO agent?
Example
Let's consider the following training parameters:
n_steps= 100n_envs= 2batch_size= 50n_epochs= 3epochs= 2
Question
$\implies$ What is total_timesteps?
$\implies$ What is the total number of batches n_batch in 1 epoch?
$\implies$ What is the total number of model updates?
Training time!
Now, set the config below and train your first reinforcement learning agent!
Apart from the reward definition, time_reward, etc. that we discussed before. Below are some other configurations that you can change:
net_arch: architecture of the policy network (# of neurons in each layer)gamma: Discount factor of the RL problem. Set lower to make rewards now more important than rewards later (usually above 0.9)normalize_observation: Normalize observations throughout training by fitting a running mean and standard deviation of themnormalize_reward: Normalize rewards throughout training by fitting a running mean and standard deviation of them
# Feel free to change some of the configurations here.
config = {
"n_envs": 40,
"n_steps": 50,
"batch_size": 100,
"n_epochs": 10,
"total_timesteps": 200_000,
"abort_if_off_screen": False,
"action_mode": "delta",
"gamma": 0.99,
"frame_stack": None,
"net_arch": [64, 64],
"normalize_observation": True,
"normalize_reward": True,
"rescale_action": (-3, 3),
"reward_mode": "negative_objective",
"run_name": names.get_full_name(),
"target_sigma_x_threshold": None,
"target_sigma_y_threshold": None,
"threshold_hold": 5,
"time_limit": 25,
"time_reward": -0.0,
}
Questions
Looking at the config dictionary in the cell above:
$\implies$ How many epochs does it correspond to?
$\implies$ How many model updates (backpropagation) would you be doing in total?
You will train the agent by executing the cell below:
# Toggle comment to re-run the training (can take very long)
%time train_ares_ea(config)
==> Training agent "Marie Willis" Eval num_timesteps=20000, episode_reward=-14.00 +/- 1.08 Episode length: 25.00 +/- 0.00 New best mean reward! Eval num_timesteps=40000, episode_reward=-6.88 +/- 0.79 Episode length: 25.00 +/- 0.00 New best mean reward! Eval num_timesteps=60000, episode_reward=-6.28 +/- 1.96 Episode length: 25.00 +/- 0.00 New best mean reward! Eval num_timesteps=80000, episode_reward=-4.76 +/- 0.96 Episode length: 25.00 +/- 0.00 New best mean reward! Eval num_timesteps=100000, episode_reward=-4.57 +/- 0.50 Episode length: 25.00 +/- 0.00 New best mean reward! Eval num_timesteps=120000, episode_reward=-5.31 +/- 1.91 Episode length: 25.00 +/- 0.00 Eval num_timesteps=140000, episode_reward=-5.31 +/- 1.02 Episode length: 25.00 +/- 0.00 Eval num_timesteps=160000, episode_reward=-4.97 +/- 0.40 Episode length: 25.00 +/- 0.00 Eval num_timesteps=180000, episode_reward=-4.77 +/- 0.52 Episode length: 25.00 +/- 0.00 Eval num_timesteps=200000, episode_reward=-5.42 +/- 1.10 Episode length: 25.00 +/- 0.00 CPU times: user 8min 22s, sys: 1.35 s, total: 8min 23s Wall time: 8min 24s
Training metrics
Let's look at the training metrics to see how the agent did.
Comment out the following line and set agent_under_investigation to the name of your agent, to check its training history.
agent_under_investigation = config["run_name"]
# agent_under_investigation = "Donna Brown"
# Training curves from this training
# Change `config["run_name"` to `"ml_worksop` to see curves from example training.
plot_ares_ea_training_history(agent_under_investigation)

Check the videos
To look at videos of the agent during training:
- find the first output line of the training cell. Your agent should have a name (e.g. Fred Rogers).
- Find the subdirectory
utils/recordings/. - There should be a directory for the name of your agent with video files in it. The
ml_workshopdirectory contains videos from an example training.
Agent evaluation
Run the following cell to evaluate your agent. This is the mean deviation of the beam parameters from the target. Lower results are better.If you are training agents that include the dipoles, set the functions argument include_position=True.
plt.figure(figsize = (7,4))
evaluate_ares_ea_agent(agent_under_investigation, include_position=False, n=2000)
Evaluation results (2000 evaluations) ---------------------------------------- ==> Mean MAE = 5.207024056733189e-05 ==> RMSE = 7.323487962575908e-05 ==> Mean no. of steps = 25.0

We can also test the trained agent on a simulation.
If you want to see an example agent instead of the one you just trained, set agent_name="ml_workshop".
# Run final agent
agent_name = agent_under_investigation
loaded_model = PPO.load(f"utils/models/{agent_name}/model")
loaded_config = read_from_yaml(f"utils/models/{agent_name}/config")
env = make_env(loaded_config, record_video=True)
env = NotVecNormalize(env, f"utils/models/{agent_name}/normalizer")
done = False
observation = env.reset()
while not done:
action, _ = loaded_model.predict(observation)
observation, reward, done, info = env.step(action)
img = env.render(mode="rgb_array")
ax.imshow(img)
display(fig)
clear_output(wait=True)
sleep(0.5)

Running in the real world
Below you can see one of our final trained agents optimising position and focus of the beam on the real ARES accelerator.
Keep in mind that this agent has never seen the real accelerator before. All it has ever seen is a very simple linear beam dynamics simulation. Despite that it performs well on the real accelerator where all kinds of other effects come into the mix.
Note that this does not happen by itself and is the result of various careful decisions when designing the traiing setup.
Once trained, the agent is, however, trivial to use and requires no futher tuning or knowledge of RL.
# Show polished donkey running (on real accelerator)
show_video("utils/real_world_episode_recording.mp4")
Further Resources
Getting started in RL¶
- OpenAI Spinning Up - Very understandable explainations on RL and the most popular algorithms acompanied by easy-to-read Python implementations.
- Reinforcement Learning with Stable Baselines 3 - YouTube playlist giving a good introduction on RL using Stable Baselines3.
- Build a Doom AI Model with Python - Detailed 3h tutorial of applying RL using DOOM as an example.
- An introduction to Reinforcement Learning - Brief introdution to RL.
- An introduction to Policy Gradient methods - Deep Reinforcement Learning - Brief introduction to PPO.
Further Resources
Papers¶
- Learning-based optimisation of particle accelerators under partial observability without real-world training - Tuning of electron beam properties on a diagnostic screen using RL.
- Sample-efficient reinforcement learning for CERN accelerator control - Beam trajectory steering using RL with a focus on sample-efficient training.
- Autonomous control of a particle accelerator using deep reinforcement learning - Beam transport through a drift tube linac using RL.
- Basic reinforcement learning techniques to control the intensity of a seeded free-electron laser - RL-based laser alignment and drift recovery.
- Real-time artificial intelligence for accelerator control: A study at the Fermilab Booster - Regulation of a gradient magnet power supply using RL and real-time implementation of the trained agent using field-programmable gate arrays (FPGAs).
- Magnetic control of tokamak plasmas through deep reinforcement learning - Landmark paper on RL for controling a real-world physical system (plasma in a tokamak fusion reactor).
Further Resources
Literature¶
- Reinforcement Learning: An Introduction - Standard text book on RL.
Packages¶
- Gym - Defacto standard for implementing custom environments. Also provides a library of RL tasks widely used for benchmarking.
- Stable Baslines3 - Provides reliable, benchmarked and easy-to-use implementations of the most important RL algorithms.
- Ray RLlib - Part of the Ray Python package providing implementations of various RL algorithms with a focus on distributed training.