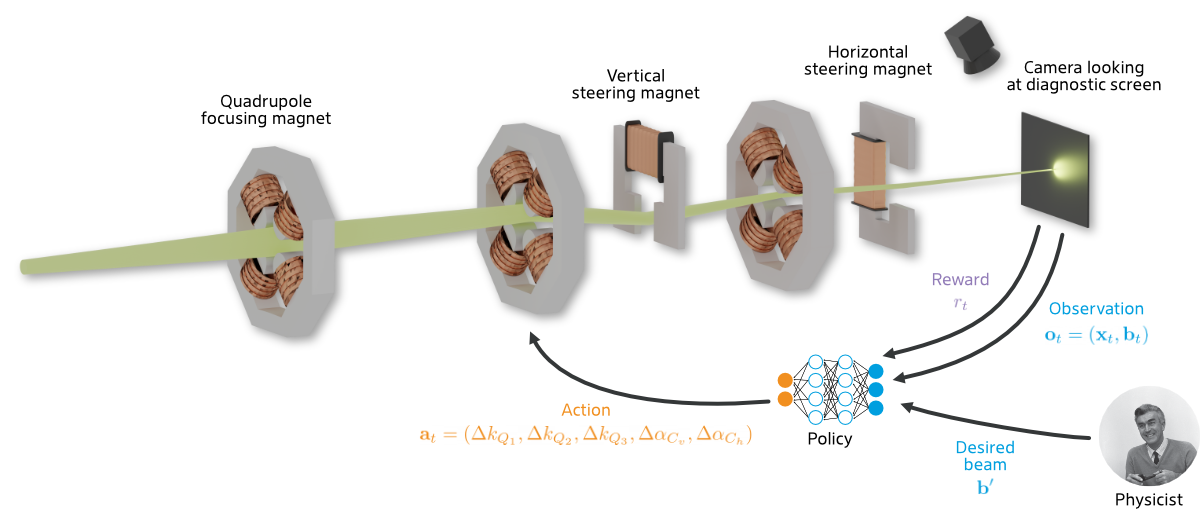
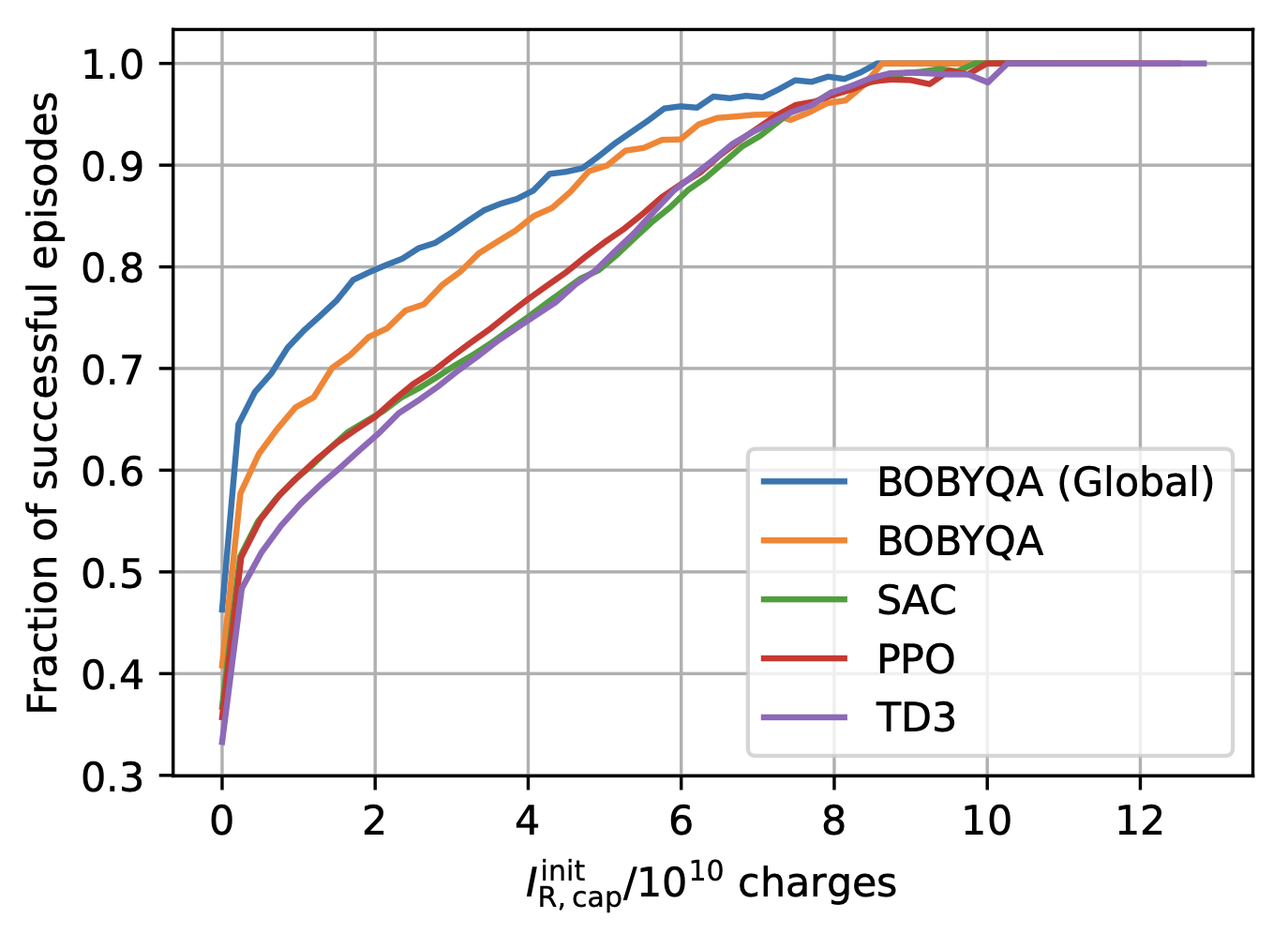
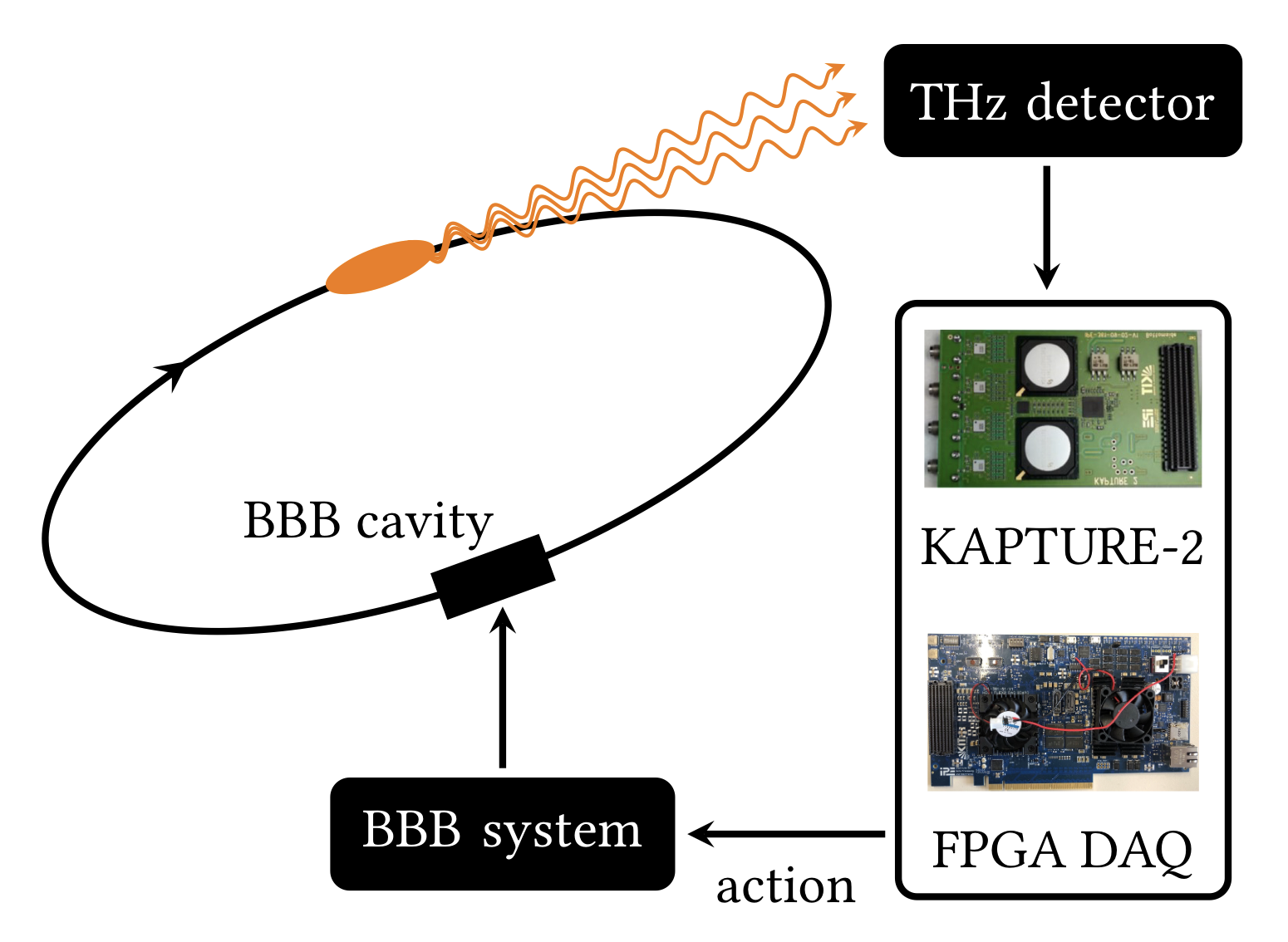
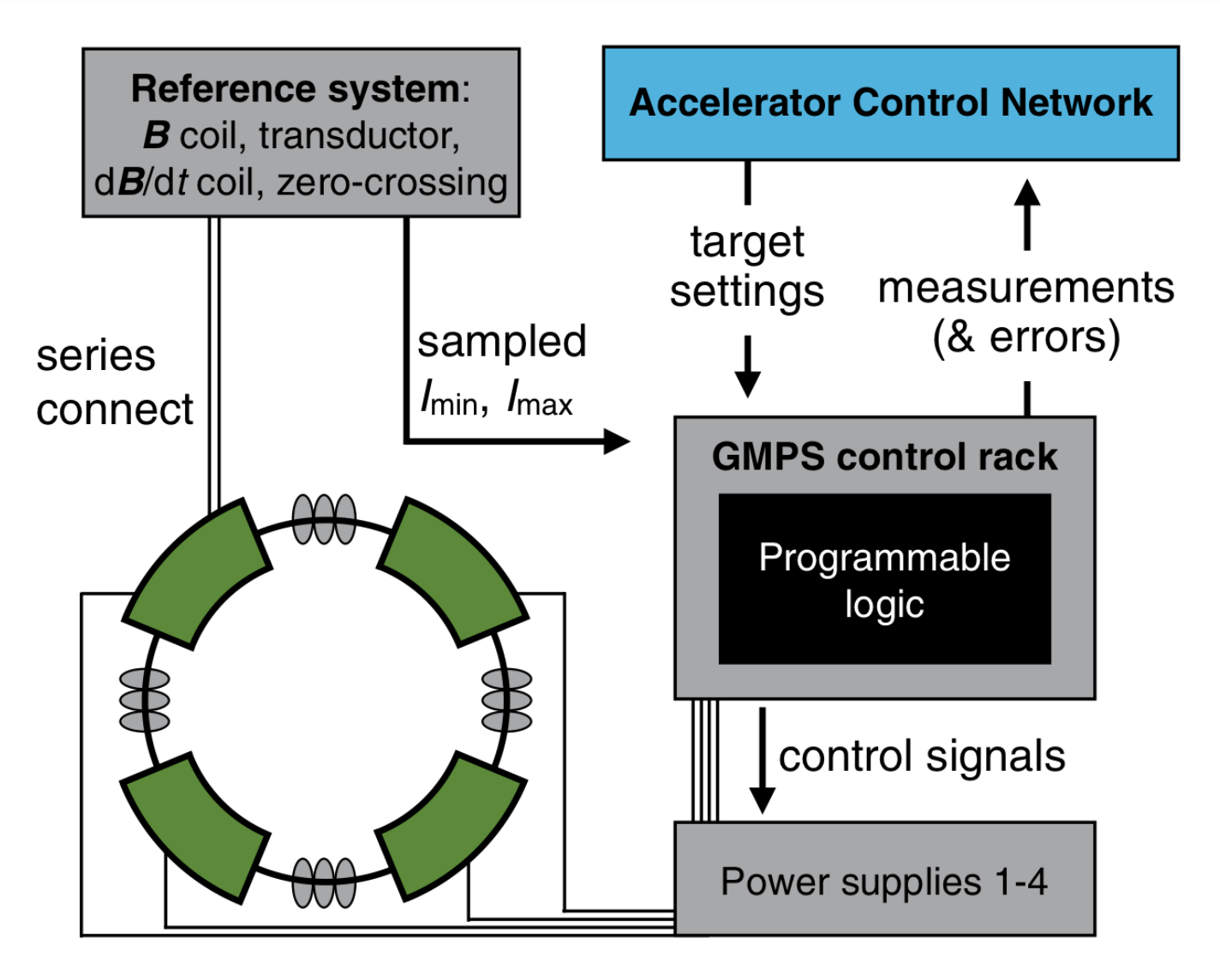
T. Boltz
Karlsruhe Insitute of Technology KIT
PhD thesis
Abstract At the time this thesis is written, the world finds itself amidst and partly in the process of recovering from the COVID-19 pandemic caused by the SARS-Cov-2 virus. One major contribution to the worldwide efforts of bringing this pandemic to an end are the vaccines developed by different research teams all around the globe. Produced in a remarkably short time frame, a crucial first step for the discovery of these vaccines was mapping out the atomic structure of the proteins making up the virus and their interactions. Due to the bright X-rays required in the process, synchrotron light sources play an active role in the ongoing efforts of accomplishing that goal. Synchrotron light sources are particle accelerators that are capable of providing intense electromagnetic radiation by accelerating packages of electrons, called bunches, and forcing them on curved trajectories. Besides the support of research on the SARS-Cov-2 virus, the remarkable properties of synchrotron radiation lead to a multitude of applications in a variety of scientific fields such as materials science, geology, biology and medicine. As a special form of synchrotron radiation, this thesis is concerned with the coherent synchrotron radiation (CSR) generated by short electron bunches in a storage ring. At wavelengths larger than the size of the emitting electron structure, the particles within a bunch radiate coherently. This coherent emission of synchrotron radiation scales with the number of involved particles and can thus enhance the intensity of the emitted radiation by several orders of magnitude. As a consequence, modern synchrotron light sources, such as the Karlsruhe Research Accelerator (KARA) at the Karlsruhe Institute of Technology (KIT), are deliberately operating with short bunch lengths to extend the radiated CSR spectrum to higher frequencies and to increase the intensity of the emitted radiation. Yet, the continuous reduction of the bunch length at high beam intensities eventually leads to complex longitudinal dynamics caused by the self-interaction of the electron bunches with their own emitted CSR. This phenomenon, generally referred to as micro-bunching or micro-wave instability, can lead to the formation of dynamically changing micro-structures within the charge distribution of the electron bunches and thus to a uctuating emission of CSR. Moreover, it can cause oscillations of the bunch length and the energy spread, which can be detrimental to the operation of a synchrotron light source. On the other hand, as electron structures smaller than the full electron bunch, the micro-structures created by the instability lead to an increased emission of CSR at frequencies up to the THz frequency range. The instability can thus also be beneficial for a variety of applications that rely on intense radiation in that particular frequency range.
...

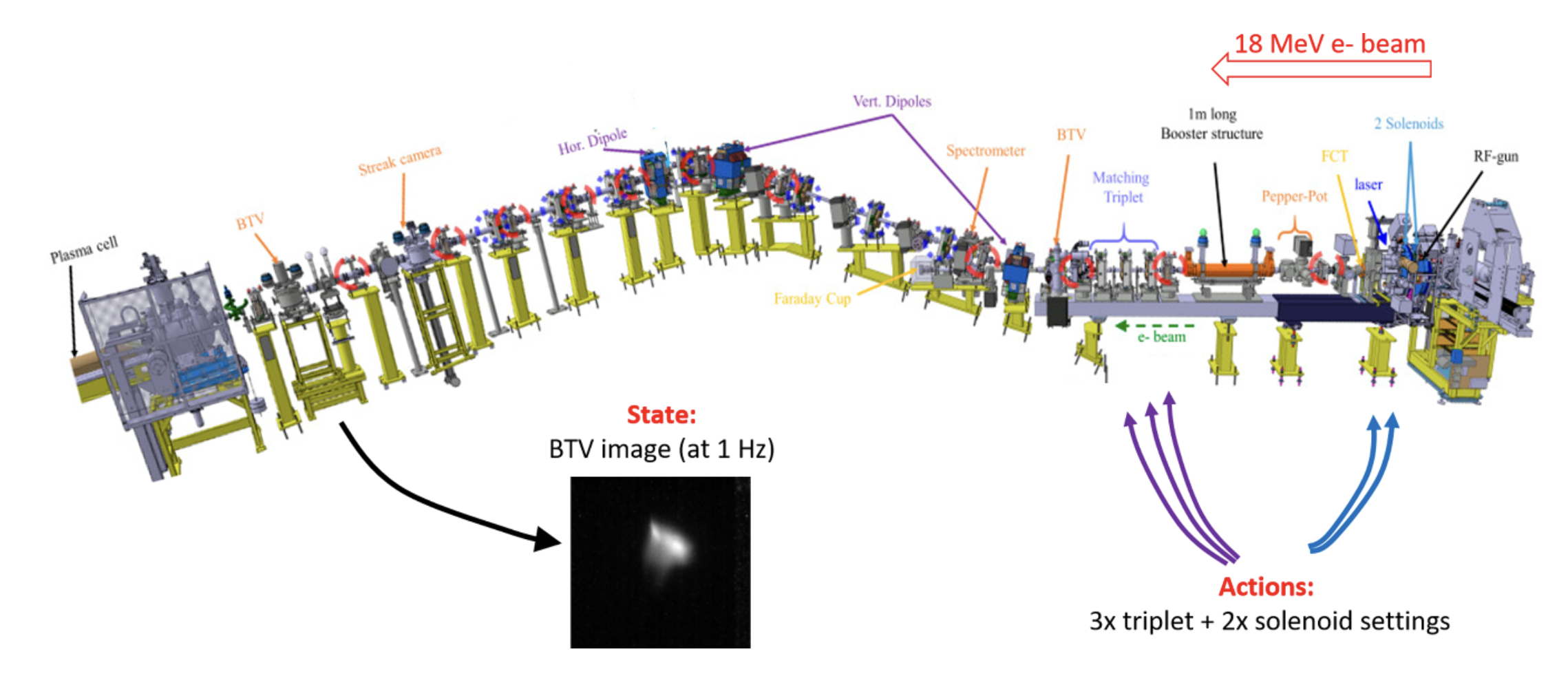
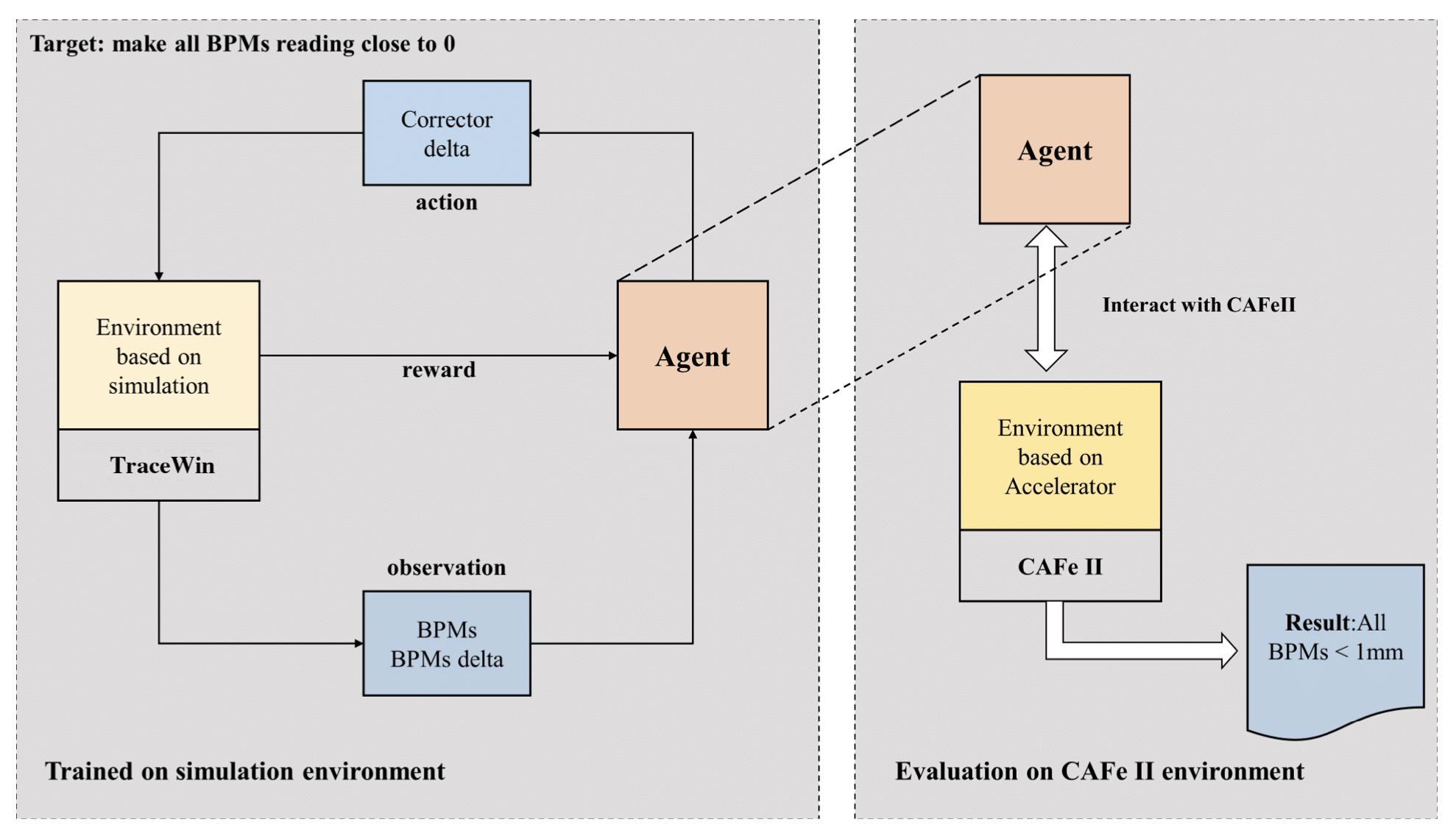

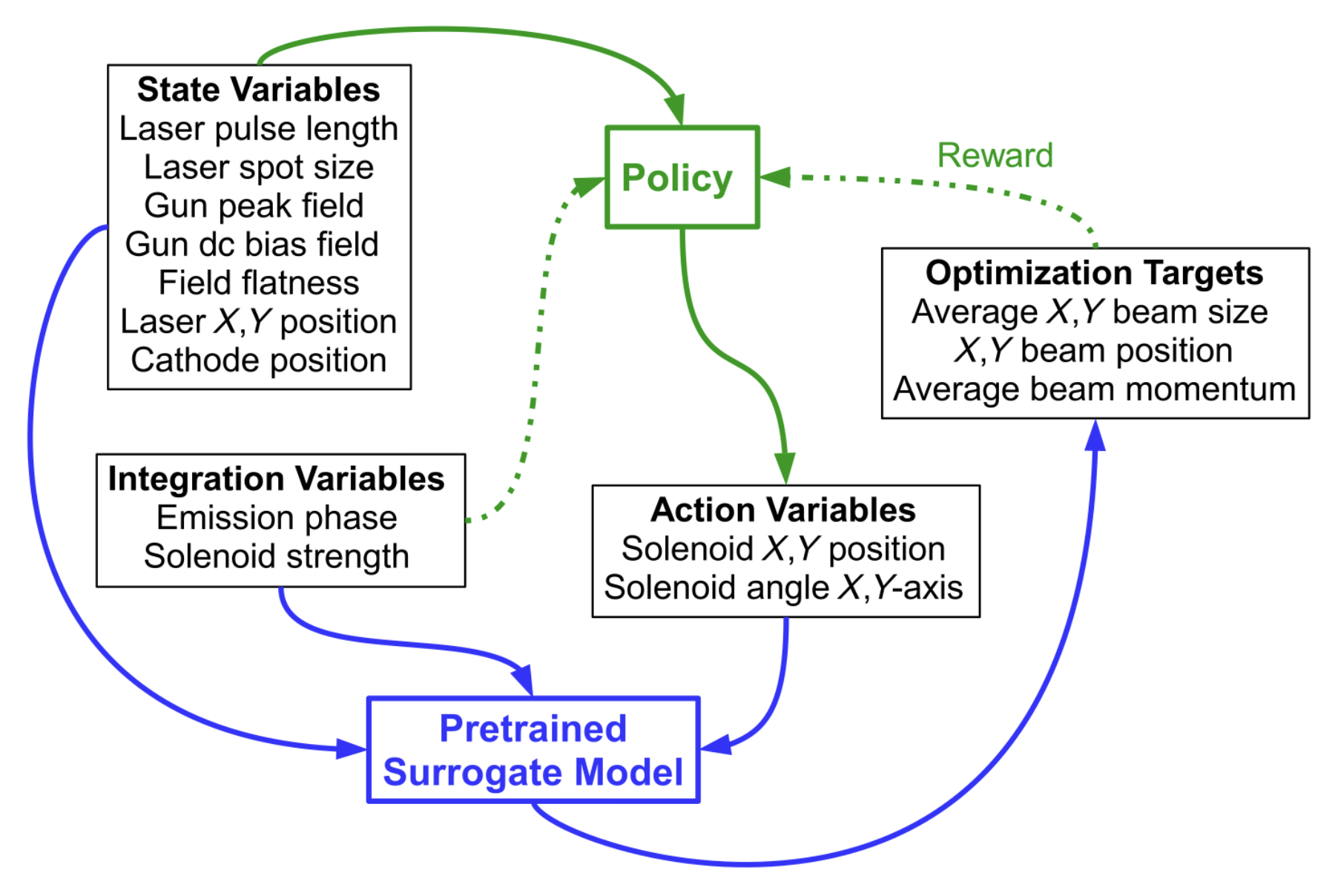
![Episodes from the best NAF2 agent and the PI controller with the same initial states and with a varying additive Gaussian action noise with zero mean and standard deviation as a percentage of the half action space [0, 1]. (A) 0%, (B) 10%, (C) 25%, and (D) 50% Gaussian action noise.](https://RL4aa.github.io/imgs/grech2022application.png)