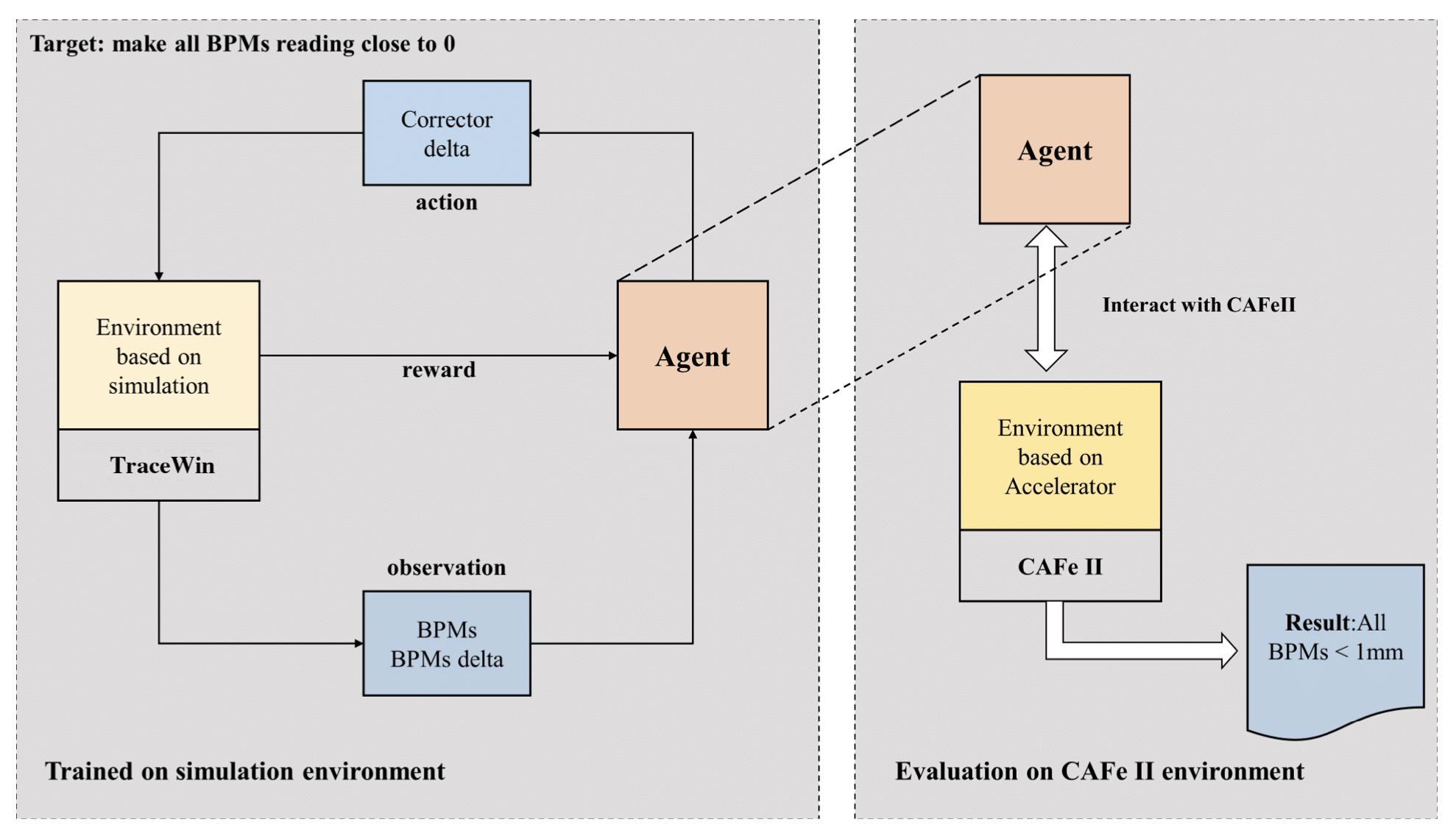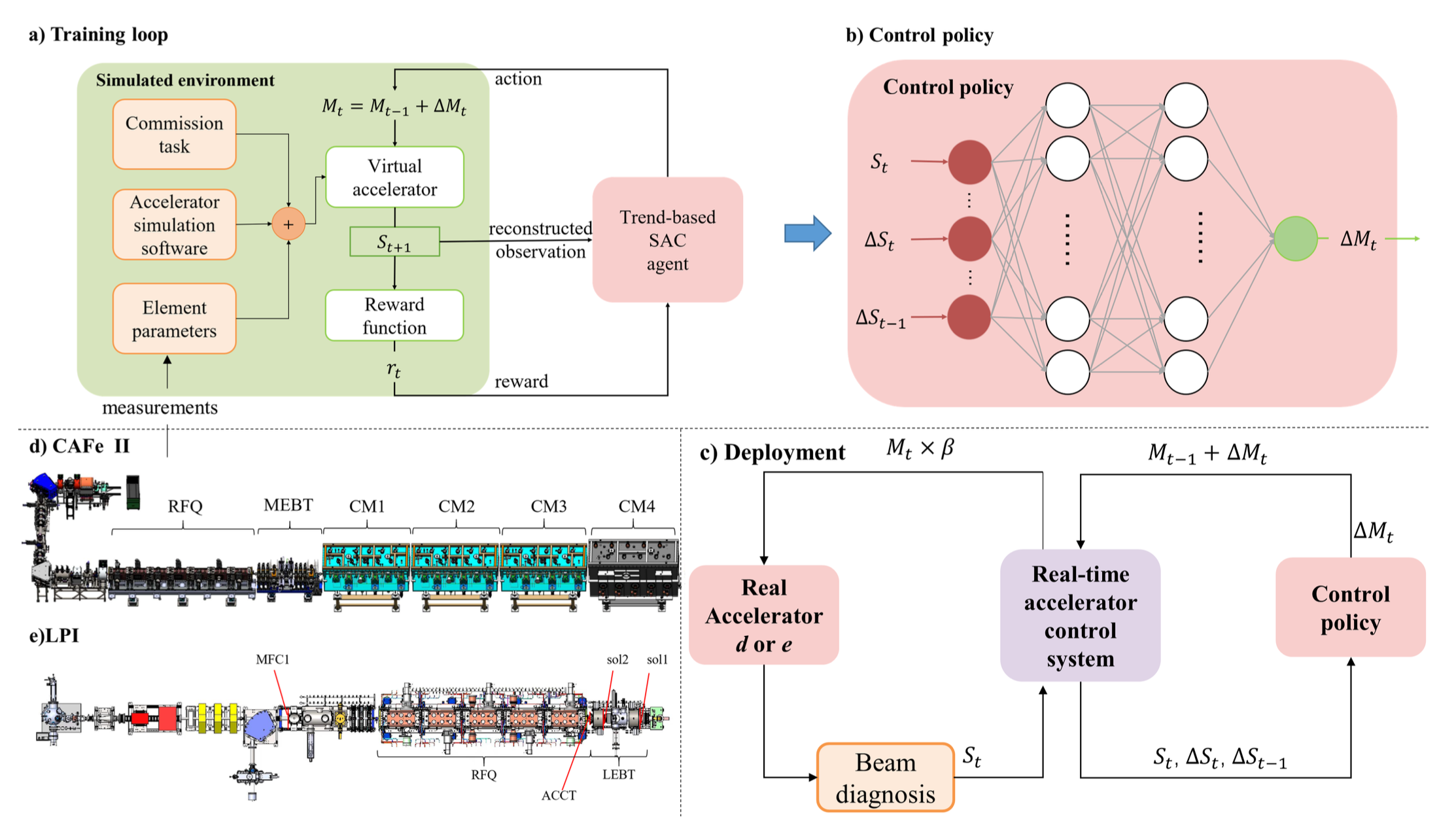
Trend-Based SAC Beam Control Method with Zero-Shot in Superconducting Linear Accelerator
X. Chen, X. Qi, C. Su, Y. He, Z. Wang, K. Sun, C. Jin, W. Chen, S. Liu, X. Zhao, D. Jia, M. Yi Chinese Academy of Sciences arXiv Abstract The superconducting linear accelerator is a highly flexiable facility for modern scientific discoveries, necessitating weekly reconfiguration and tuning. Accordingly, minimizing setup time proves essential in affording users with ample experimental time. We propose a trend-based soft actor-critic(TBSAC) beam control method with strong robustness, allowing the agents to be trained in a simulated environment and applied to the real accelerator directly with zero-shot. To validate the effectiveness of our method, two different typical beam control tasks were performed on China Accelerator Facility for Superheavy Elements (CAFe II) and a light particle injector(LPI) respectively. The orbit correction tasks were performed in three cryomodules in CAFe II seperately, the time required for tuning has been reduced to one-tenth of that needed by human experts, and the RMS values of the corrected orbit were all less than 1mm. The other transmission efficiency optimization task was conducted in the LPI, our agent successfully optimized the transmission efficiency of radio-frequency quadrupole(RFQ) to over 85% within 2 minutes. The outcomes of these two experiments offer substantiation that our proposed TBSAC approach can efficiently and effectively accomplish beam commissioning tasks while upholding the same standard as skilled human experts. As such, our method exhibits potential for future applications in other accelerator commissioning fields. ...