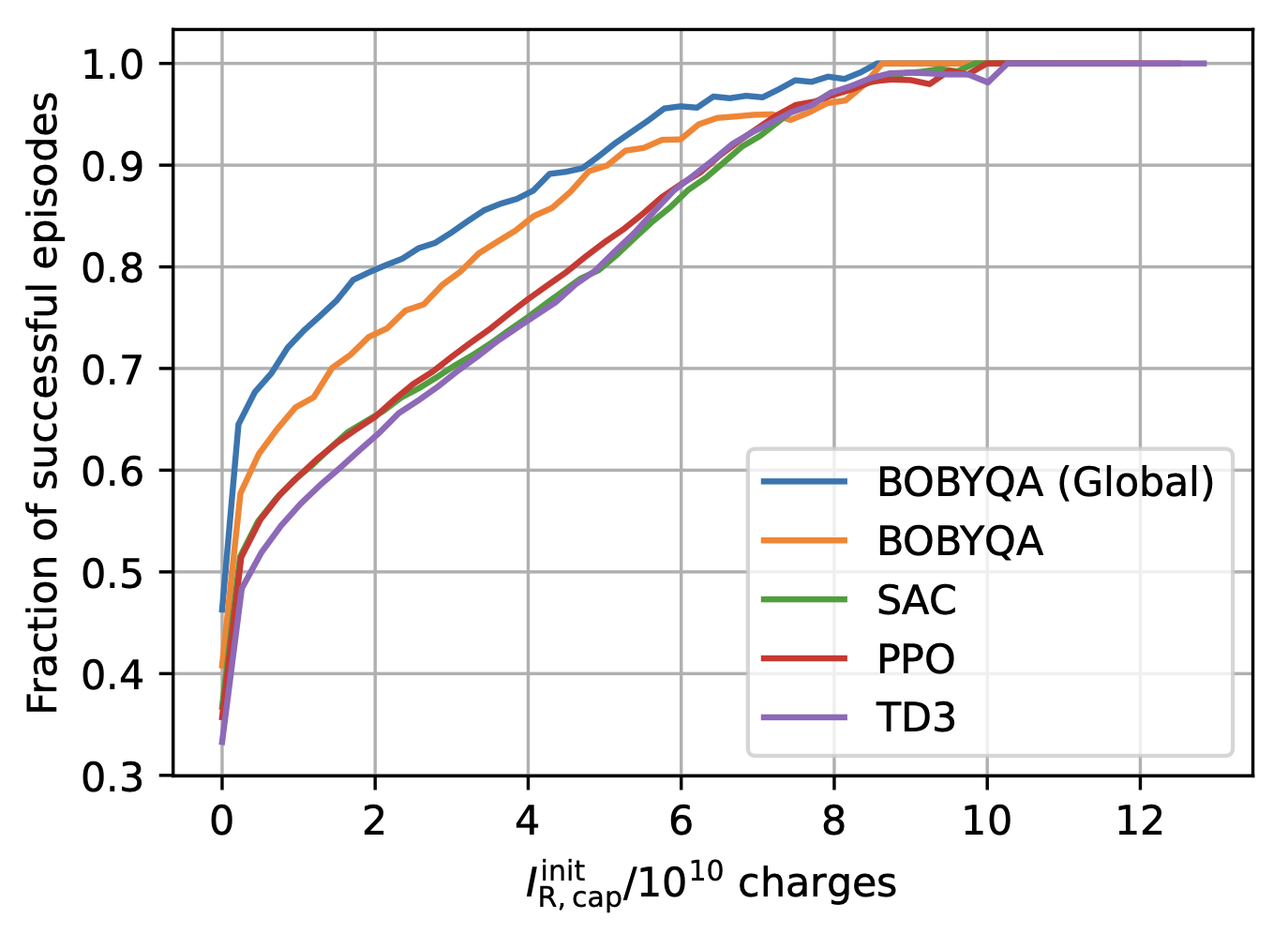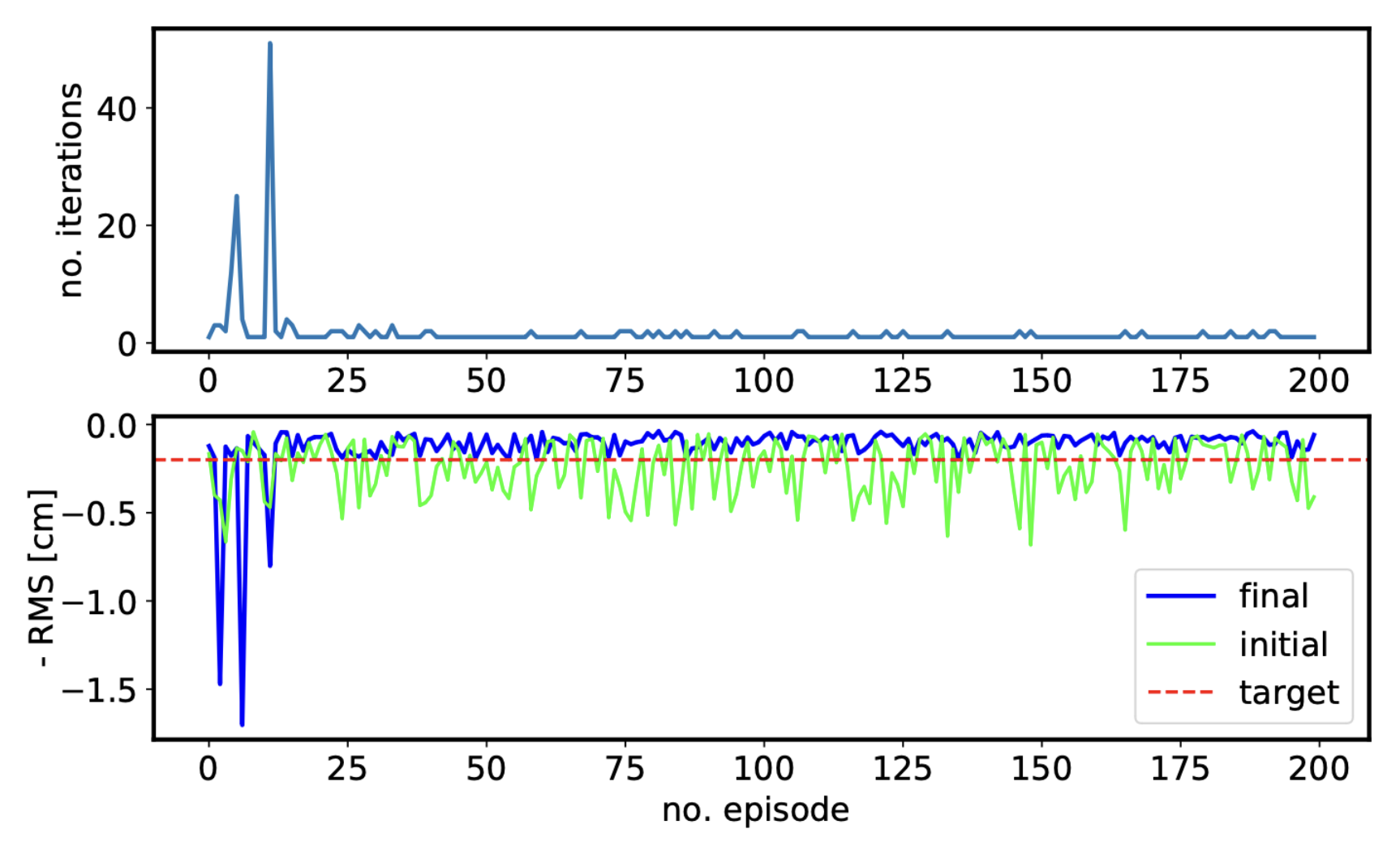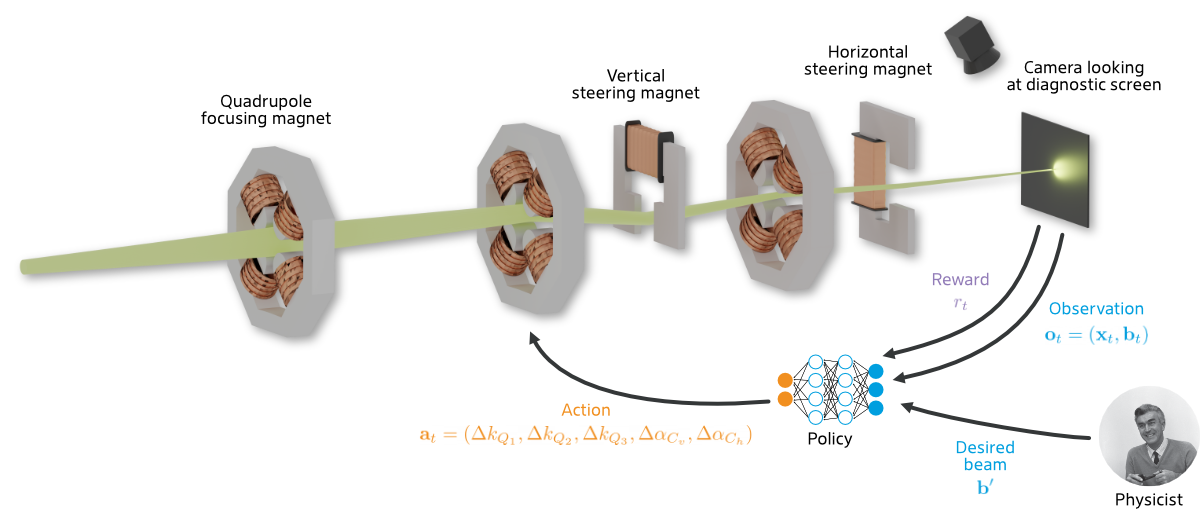
Learning-based Optimisation of Particle Accelerators Under Partial Observability Without Real-World Training
J. Kaiser, O. Stein, A. Eichler Deutsches Elektronen-Synchrotron DESY 39th International Conference on Machine Learning Abstract In recent work, it has been shown that reinforcement learning (RL) is capable of solving a variety of problems at sometimes super-human performance levels. But despite continued advances in the field, applying RL to complex real-world control and optimisation problems has proven difficult. In this contribution, we demonstrate how to successfully apply RL to the optimisation of a highly complex real-world machine – specifically a linear particle accelerator – in an only partially observable setting and without requiring training on the real machine. Our method outperforms conventional optimisation algorithms in both the achieved result and time taken as well as already achieving close to human-level performance. We expect that such automation of machine optimisation will push the limits of operability, increase machine availability and lead to a paradigm shift in how such machines are operated, ultimately facilitating advances in a variety of fields, such as science and medicine among many others. ...