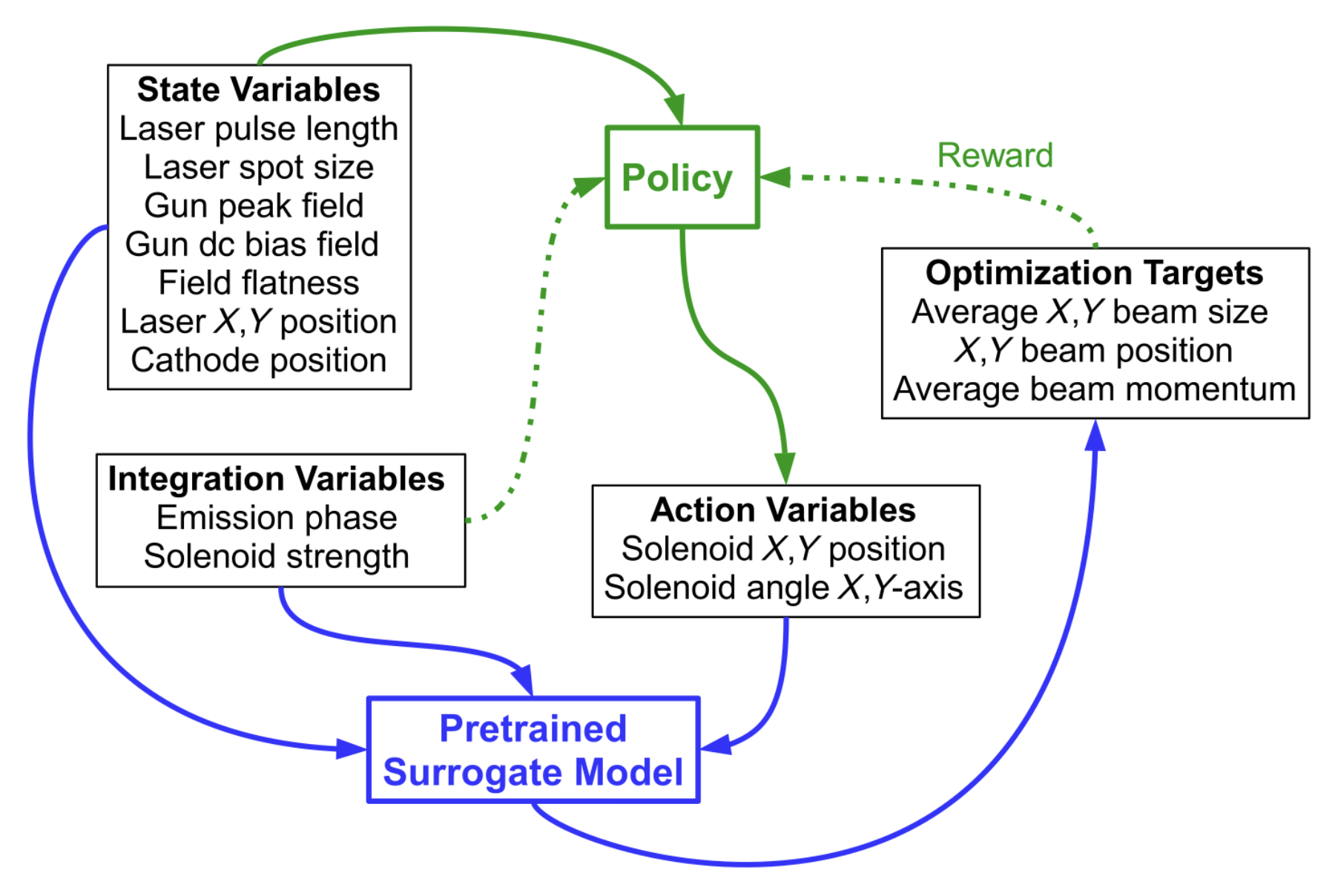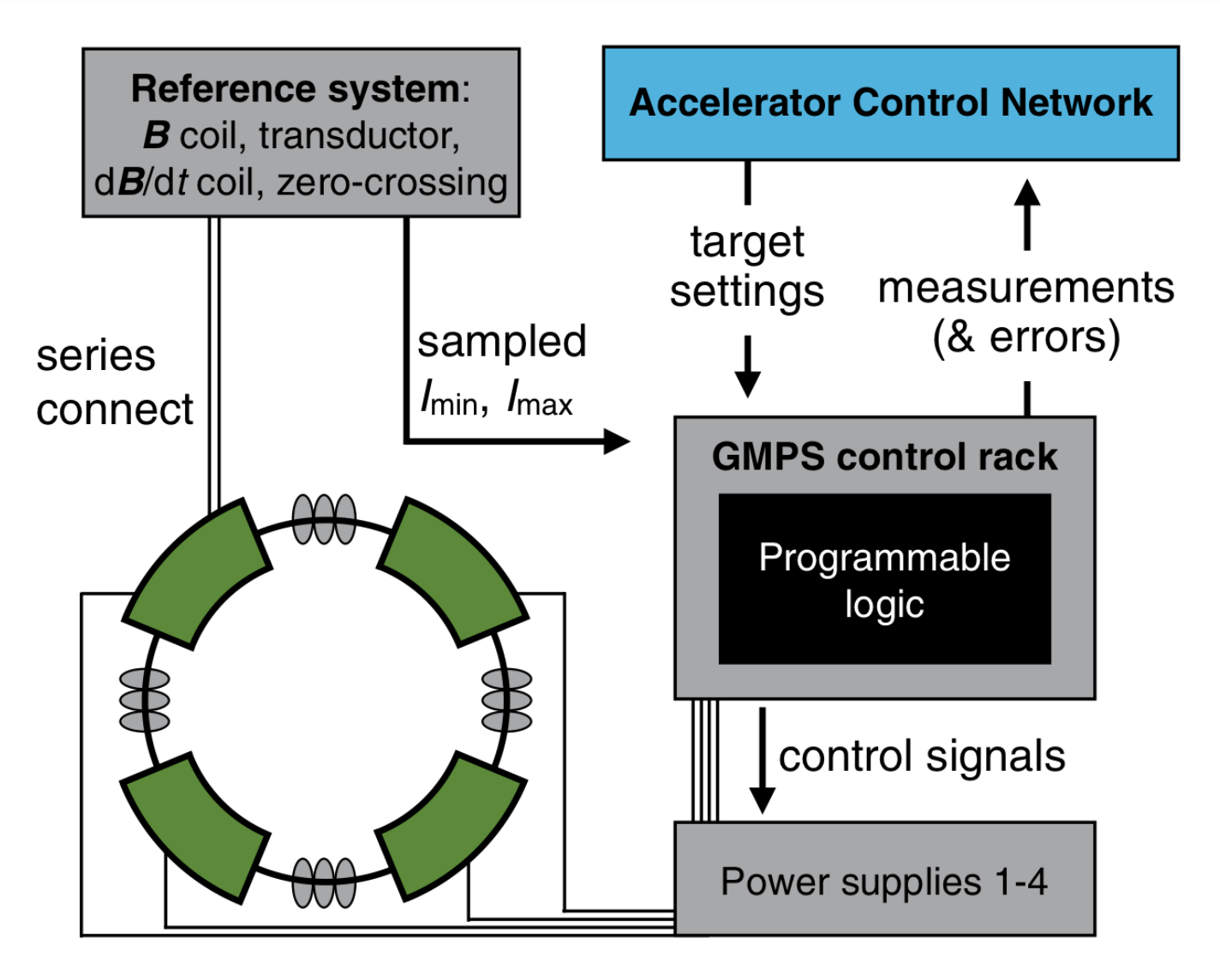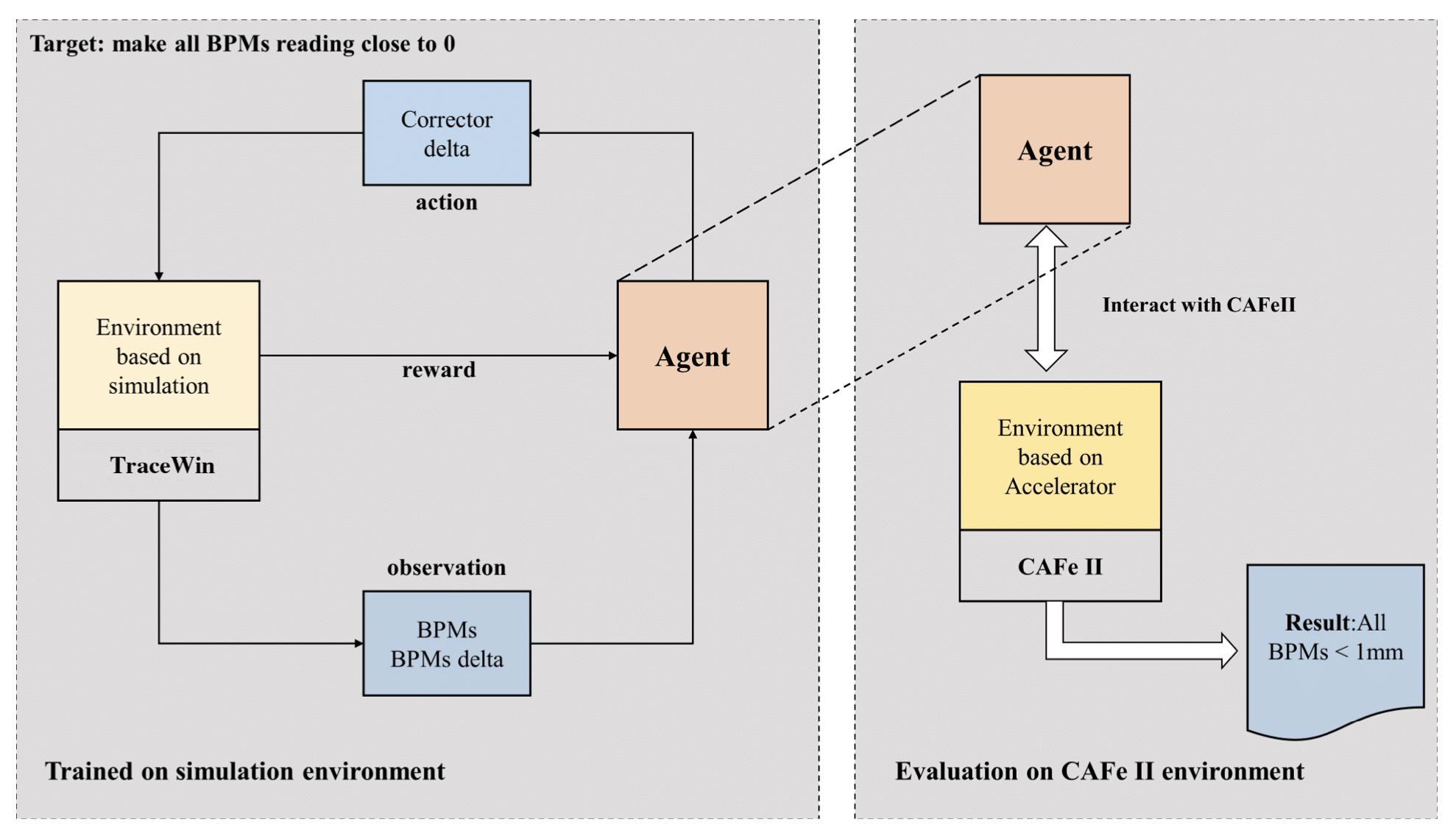
Orbit Correction Based on Improved Reinforcement Learning Algorithm
X. Chen, Y. Jia, X. Qi, Z. Wang, Y. He Chinese Academy of Sciences Physical Review Accelerators and Beams Abstract Recently, reinforcement learning (RL) algorithms have been applied to a wide range of control problems in accelerator commissioning. In order to achieve efficient and fast control, these algorithms need to be highly efficient, so as to minimize the online training time. In this paper, we incorporated the beam position monitor trend into the observation space of the twin delayed deep deterministic policy gradient (TD3) algorithm and trained two different structure agents, one based on physical prior knowledge and the other using the original TD3 network architecture. Both of the agents exhibit strong robustness in the simulated environment. The effectiveness of the agent based on physical prior knowledge has been validated in a real accelerator. Results show that the agent can overcome the difference between simulated and real accelerator environments. Once the training is completed in the simulated environment, the agent can be directly applied to the real accelerator without any online training process. The RL agent is deployed to the medium energy beam transport section of China Accelerator Facility for Superheavy Elements. Fast and automatic orbit correction is being tested with up to ten degrees of freedom. The experimental results show that the agents can correct the orbit to within 1 mm. Moreover, due to the strong robustness of the agent, when a trained agent is applied to different lattices of different particles, the orbit correction can still be completed. Since there are no online data collection and training processes, all online corrections are done within 30 s. This paper shows that, as long as the robustness of the RL algorithm is sufficient, the offline learning agents can be directly applied to online correction, which will greatly improve the efficiency of orbit correction. Such an approach to RL may find promising applications in other areas of accelerator commissioning. ...