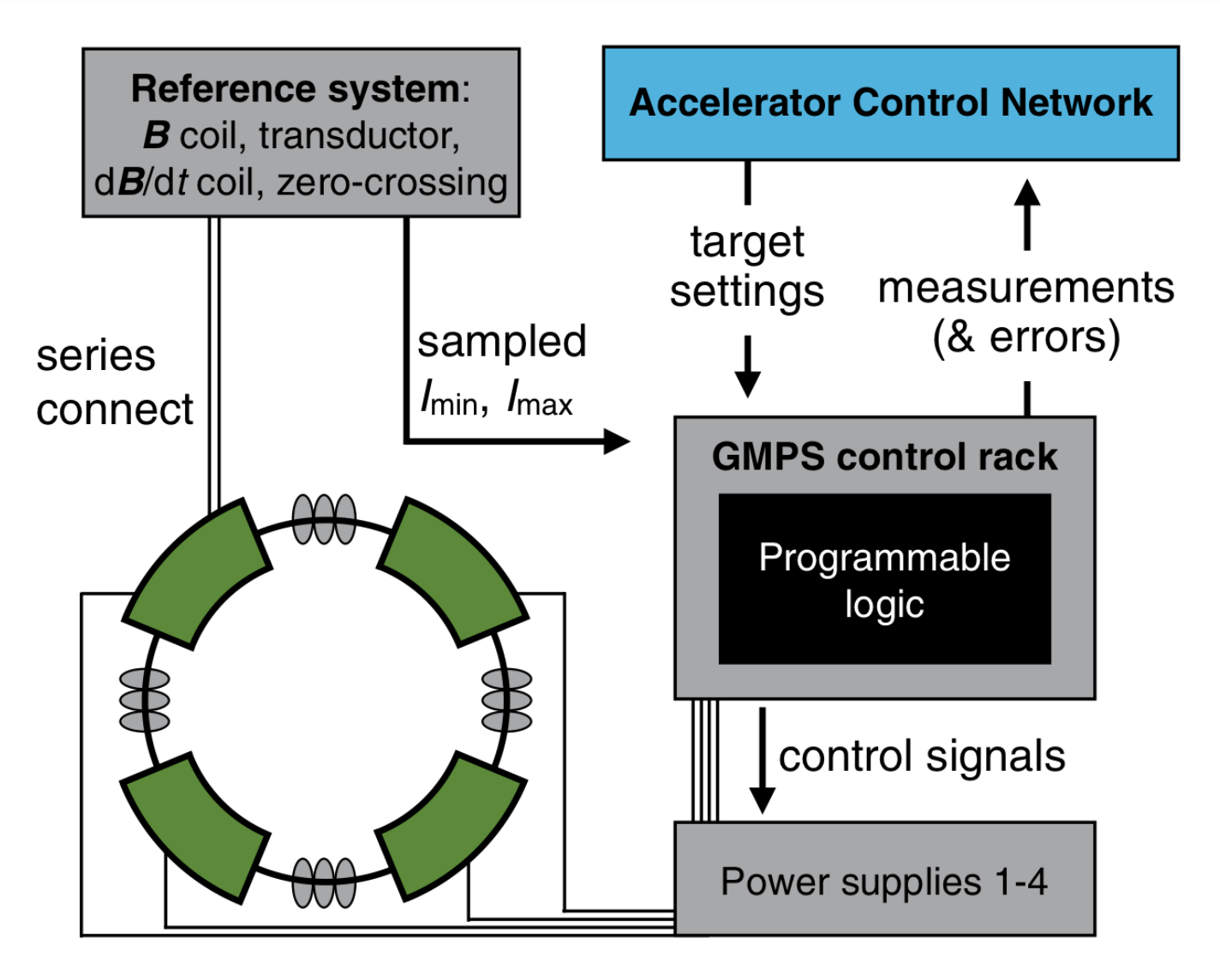
Real-time artificial intelligence for accelerator control: A study at the Fermilab Booster
J. St. John1, C. Herwig1, D. Kafkes1, J. Mitrevski1, W. A. Pellico1, G. N. Perdue1, A. Quintero-Parra1, B. A. Schupbach1, K. Seiya1, N. Tran1, M. Schram2, J. M. Duarte3, Y. Huang4, R. Keller5 1Fermi National Accelerator Laboratory, 2Thomas Jefferson National Accelerator Laboratory, 3University of California San Diego, 4Pacific Northwest National Laboratory, 5Columbia University Physical Review Accelerators and Beams Abstract We describe a method for precisely regulating the gradient magnet power supply (GMPS) at the Fermilab Booster accelerator complex using a neural network trained via reinforcement learning. We demonstrate preliminary results by training a surrogate machine-learning model on real accelerator data to emulate the GMPS, and using this surrogate model in turn to train the neural network for its regulation task. We additionally show how the neural networks to be deployed for control purposes may be compiled to execute on field-programmable gate arrays (FPGAs), and show the first machine-learning based control algorithm implemented on an FPGA for controls at the Fermilab accelerator complex. As there are no surprise latencies on an FPGA, this capability is important for operational stability in complicated environments such as an accelerator facility. ...