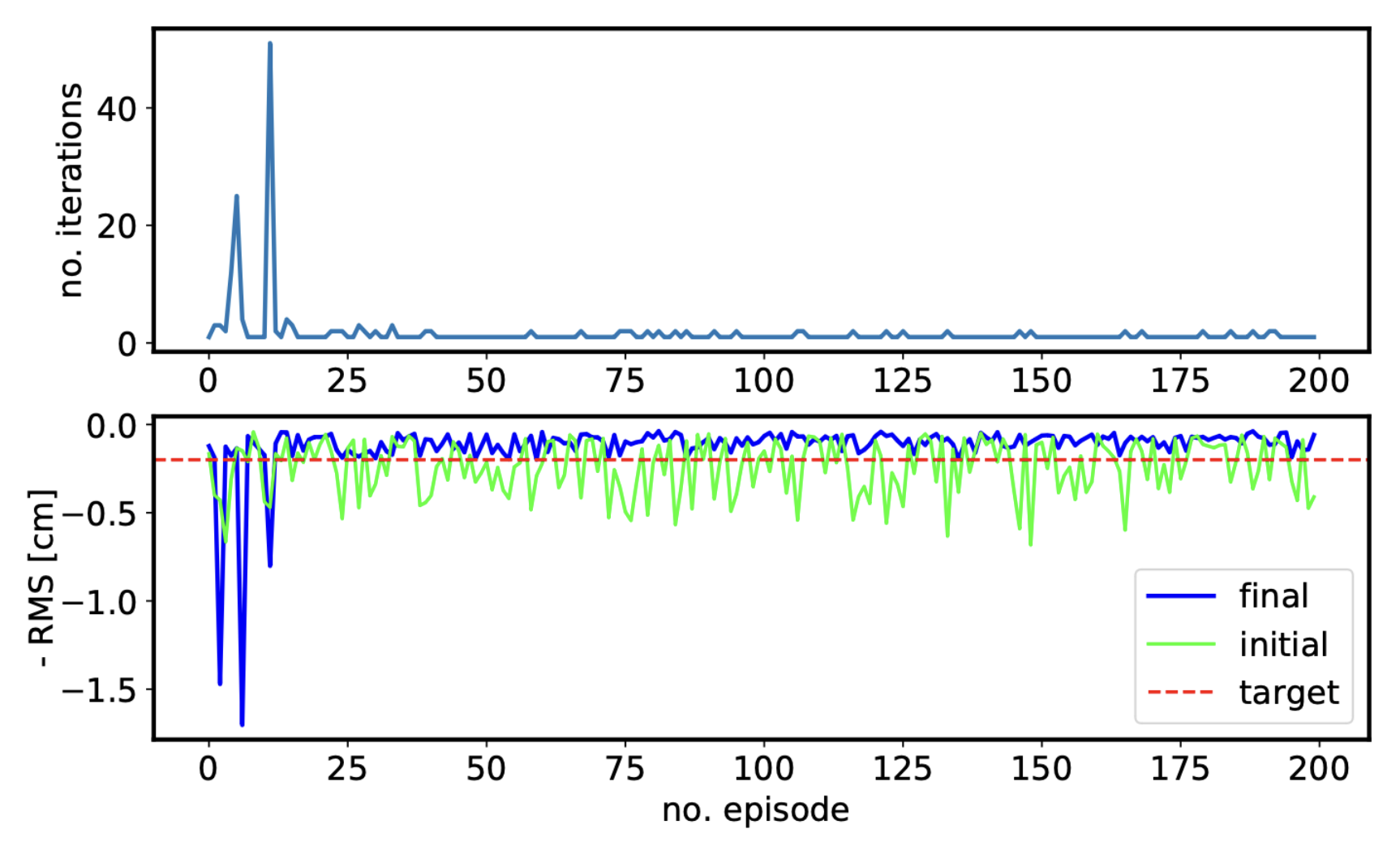
![Episodes from the best NAF2 agent and the PI controller with the same initial states and with a varying additive Gaussian action noise with zero mean and standard deviation as a percentage of the half action space [0, 1]. (A) 0%, (B) 10%, (C) 25%, and (D) 50% Gaussian action noise.](https://RL4aa.github.io/imgs/grech2022application.png)
Application of reinforcement learning in the LHC tune feedback
L. Grech1, G. Valentino1, D. Alves2 and Simon Hirlaender3 1University of Malta, 2CERN, 3University of Salzburg Frontiers in Physics Abstract The Beam-Based Feedback System (BBFS) was primarily responsible for correcting the beam energy, orbit and tune in the CERN Large Hadron Collider (LHC). A major code renovation of the BBFS was planned and carried out during the LHC Long Shutdown 2 (LS2). This work consists of an explorative study to solve a beam-based control problem, the tune feedback (QFB), utilising state-of-the-art Reinforcement Learning (RL). A simulation environment was created to mimic the operation of the QFB. A series of RL agents were trained, and the best-performing agents were then subjected to a set of well-designed tests. The original feedback controller used in the QFB was reimplemented to compare the performance of the classical approach to the performance of selected RL agents in the test scenarios. Results from the simulated environment show that the RL agent performance can exceed the controller-based paradigm. ...